Ollama switched its Apple Silicon path to MLX, added NVFP4 support, and reworked cache reuse and checkpointing. The preview targets faster prefill and decode on M5-class Macs while reducing memory pressure in long coding-agent sessions.
Ollama's Apple Silicon path now runs on MLX, which the company describes in the launch thread as its fastest implementation yet on Mac. The concrete claim is not just a framework swap: in the performance post, Ollama says M5, M5 Pro, and M5 Max use new GPU Neural Accelerators to improve both prefill and decode.
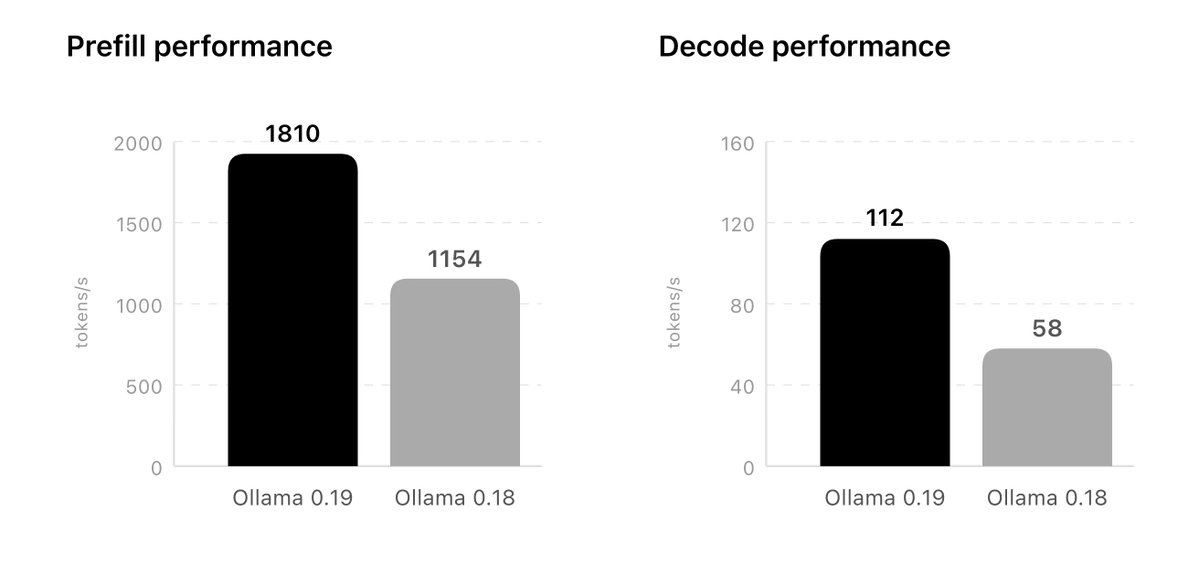
The most specific benchmark details come from Ollama's own notes around Qwen3.5-35B-A3B. In the performance post, it says the comparison used an NVFP4-quantized Qwen3.5-35B-A3B model versus the previous q4_K_M path on Ollama 0.18, and that Ollama 0.19 should push that further to 1,851 tokens/sec prefill and 134 tokens/sec decode with int4. The linked blog post gives roughly similar preview numbers and frames the gain around unified memory plus MLX integration.
The other implementation change is NVFP4 support. In the NVFP4 post, Ollama says the format maintains accuracy while reducing memory bandwidth and storage requirements, which matters because the same quantization format is already used by some inference providers. That makes local testing less of a format mismatch than running a separate desktop-only quantization path.
Ollama's cache logic changed in three ways that matter for agent workloads. In the caching post, it says cache is now reused across conversations, which should increase cache hits when branching from a shared system prompt in tools like Claude Code. It also says Ollama now stores snapshots at "intelligent locations" in prompts, reducing repeated prompt processing, and uses "smarter eviction" so shared prefixes survive longer even when older branches are dropped.
That is a practical change for local coding loops because the bottleneck is often repeated prompt prefill, not just decode speed. Ollama explicitly ties the update in the launch thread to "coding agents like Claude Code, OpenCode, or Codex," and the cache changes in the caching post are the part of the release most directly aimed at those branch-heavy sessions.
The preview currently centers on one model family: Qwen3.5-35B-A3B coding builds. In get-started instructions, Ollama says users need a Mac with more than 32GB of unified memory and provides direct commands for ollama launch claude --model qwen3.5:35b-a3b-coding-nvfp4, ollama launch openclaw --model qwen3.5:35b-a3b-coding-nvfp4, and ollama run qwen3.5:35b-a3b-coding-nvfp4.
Support is broader in intent than in shipping scope. In the future-models post, Ollama says it is working on more supported architectures and an easier import path for custom models fine-tuned on supported architectures. For now, the release is best read as a preview runtime upgrade with one accelerated coding model, plus a roadmap for wider model coverage.
Ollama is now updated to run the fastest on Apple silicon, powered by MLX, Apple's machine learning framework. This change unlocks much faster performance to accelerate demanding work on macOS: - Personal assistants like OpenClaw - Coding agents like Claude Code, OpenCode, Show more
NVFP4 support: higher quality responses and production parity Ollama now leverages NVIDIA’s NVFP4 format to maintain model accuracy while reducing memory bandwidth and storage requirements for inference workloads. As more inference providers scale inference using NVFP4 format, Show more

Improved caching for more responsiveness Ollama’s cache has been upgraded to make coding and agentic tasks more efficient. Lower memory utilization: Ollama will now reuse its cache across conversations, meaning less memory utilization and more cache hits when branching when Show more
Get started This preview release of Ollama accelerates the new Qwen3.5-35B-A3B model. Please make sure you have a Mac with more than 32GB of unified memory. Claude Code: ollama launch claude --model qwen3.5:35b-a3b-coding-nvfp4 OpenClaw: ollama launch openclaw --model Show more
Future models We are actively working to support future models. For users with custom models fine-tuned on supported architectures, we will introduce an easier way to import models into Ollama. In the meantime, we will expand the list of supported architectures. Show more