Tax AI reports 97% accuracy across 7,000 returns at 30+ accounting firms
OpenAI and Thrive described Tax AI, a self-improving tax-prep system used across 30+ firms that processed 7,000 returns and reached up to 97% accuracy. The loop turns accountant corrections into eval targets and narrow Codex fixes, showing a concrete path to vertical agents that improve after deployment.
TL;DR
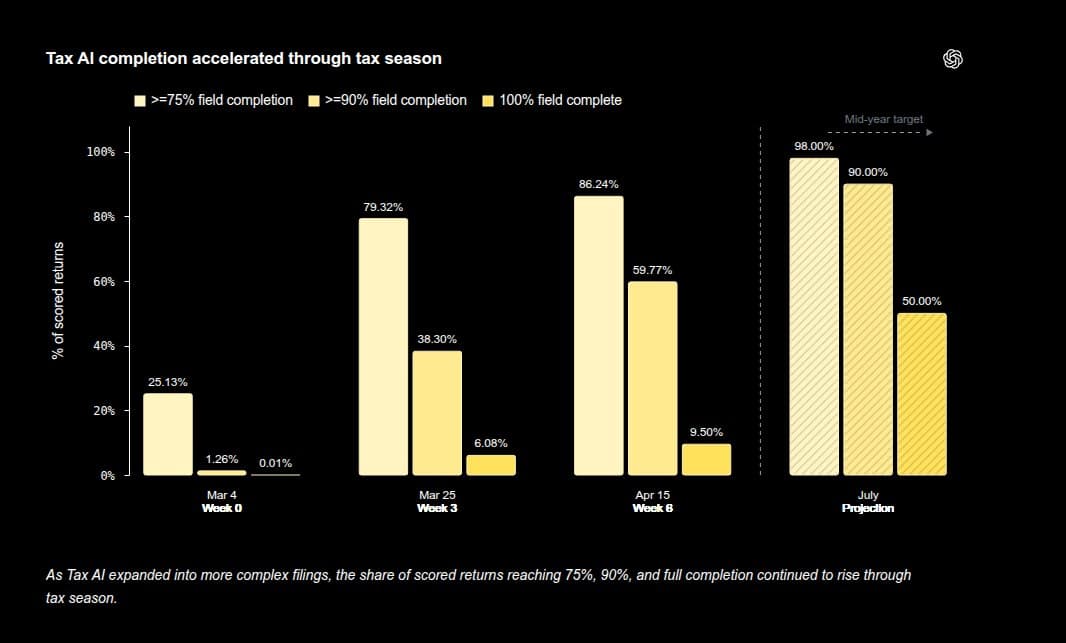
- OpenAI and Thrive say Tax AI has now processed 7,000 returns across more than 30 accounting firms, with up to 97% accuracy, about one-third less prep time, and roughly 50% higher throughput, according to OpenAIDevs' announcement and rohanpaul_ai's breakdown.
- The interesting part is not OCR alone. rohanpaul_ai's breakdown says the hard cases were messy tax workflows such as K-1s, rental schedules, notes, spreadsheets, and prior-year files that have to agree across documents.
- The product keeps a full trace from source file to final filed value, then turns repeated accountant corrections into eval targets that Codex can fix against with code, tests, and a pass condition, per OpenAIDevs' announcement and rohanpaul_ai's breakdown.
- BorisMPower's note on eval loops framed the bigger engineering lesson clearly: fast evaluation and iteration loops were the lever, which is why this reads more like a vertical agent harness than a one-shot extraction demo.
You can read OpenAI's full post, and the useful detail is how much instrumentation the system keeps: rohanpaul_ai's breakdown says every correction is tied back to source documents, extraction traces, mappings, and the final filed value. OpenAIDevs' announcement also makes the deployment scope concrete, with 30-plus firms already in the loop rather than a sandbox pilot.
Deployment numbers
The top-line claims are unusually specific for an agent case study. OpenAI's post and rohanpaul_ai's breakdown both put the rollout at 7,000 returns across 30-plus accounting firms.
The reported results break down into four numbers:
- Up to 97% accuracy
- About one-third less preparation time
- About 50% higher throughput
- Deployment across 30-plus firms and 7,000 returns
That makes this less of a lab benchmark story and more of a production workflow report with narrow, domain-specific metrics.
Correction trace
What gives the system some chance of improving after deployment is the trace it stores for every field. rohanpaul_ai's breakdown says the record includes:
- Source file
- Extracted field
- Citation
- Tax-engine mapping
- Accountant correction
- Final filed value
That is the important architectural move in OpenAI's post. A correction is not just a thumbs-down signal. It becomes a debuggable artifact with enough context to figure out whether the failure came from extraction, mapping, unsupported workflow logic, prior-year carryovers, or plain human judgment.
Codex loop
The self-improving loop is narrow on purpose. OpenAIDevs' announcement says that when reviewers fix an error, Codex traces the failure, improves the system, and tests the change before it ships.
rohanpaul_ai's breakdown adds the concrete sequence:
- Accountants correct a recurring mistake.
- Repeated corrections get promoted into eval targets.
- Codex receives a bounded task with evidence, code, tests, and a pass condition.
- The proposed fix runs against regression tests before deployment.
That is a lot more constrained than the usual "agent fixes itself" pitch. The system is learning from operator corrections by converting them into small engineering tasks.
Tax documents
The hard part was not reading standard forms. rohanpaul_ai's breakdown says the trouble came from the ugly inputs tax teams actually wrestle with:
- K-1s
- Rental schedules
- Free-form notes
- Spreadsheets
- Prior-year files
- Values that must match across multiple documents
That list is useful because it explains where the reported accuracy number is coming from. The problem space is not single-document extraction. It is cross-document consistency inside a tax workflow.
Rental-property debugging
The most concrete debugging example in the evidence is a rental-property case. rohanpaul_ai's rental-property example says the agent could inspect:
- Source documents
- Extraction traces
- Mapper behavior
- Expected outputs
- Regression tests
That is a more revealing detail than the headline metric. It suggests the product team built a workflow where tax errors can be replayed with the surrounding evidence intact, which is what makes repeated fixes testable instead of anecdotal.