Tencent releases HY-World 2.0 with WorldMirror 2.0 and editable 3D worlds
Tencent released HY-World 2.0, a multimodal world model that turns text, images, or video into editable 3D worlds, and open-sourced WorldMirror 2.0 inference code and weights. Its four-stage pipeline targets reusable scene assets rather than single-view video clips.
TL;DR
- TencentHunyuan's launch post says HY-World 2.0 takes text, images, and videos, then outputs editable 3D worlds rather than video-only demos.
- According to TencentHunyuan's technical highlights, the system is split across HY-Pano 2.0, WorldNav, WorldStereo 2.0, WorldMirror 2.0, and WorldLens.
- rohanpaul_ai's WorldMirror post and the GitHub repo both say WorldMirror 2.0 inference code and model weights are open now, while the rest of the generation stack is still rolling out.
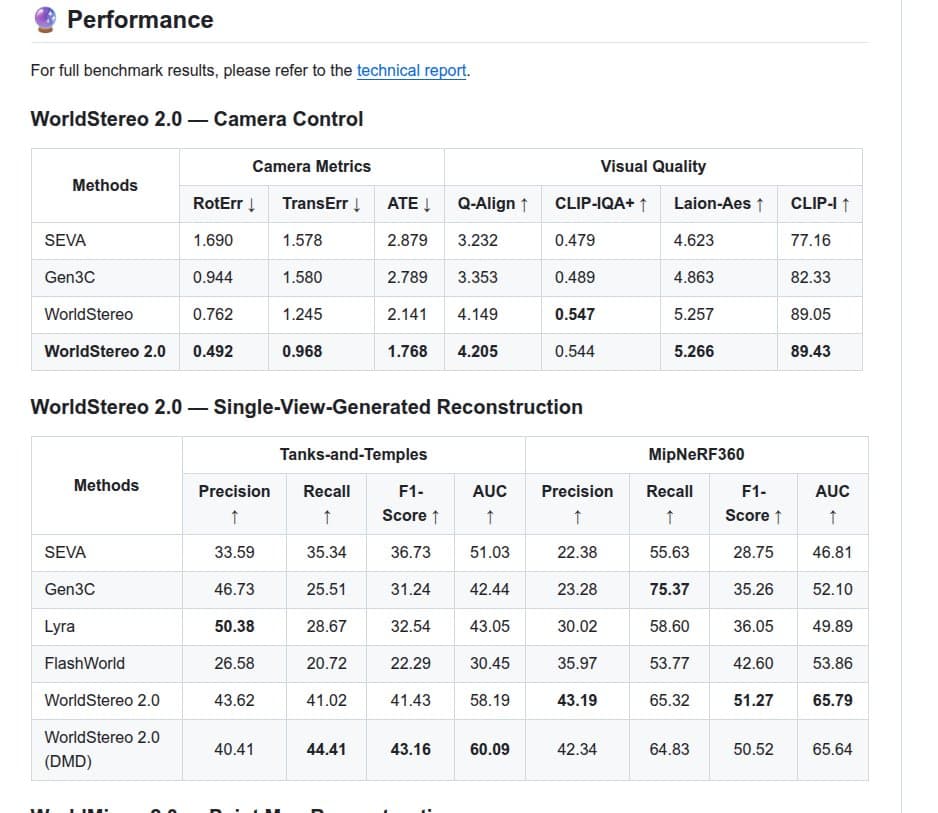
- The technical report and rohanpaul_ai's benchmark summary frame WorldStereo 2.0 as the strongest piece on camera control and reconstruction metrics in Tencent's evals.
You can read the technical report, browse the GitHub repo, and try the product page. The odd but useful detail is in the repo's open-source plan: Tencent shipped the reconstruction half first, while HY-Pano 2.0, WorldNav, and WorldStereo 2.0 are still marked coming soon.
Editable 3D outputs
Tencent is pitching HY-World 2.0 against video world models on the output format, not just on generation quality. The GitHub README says the system exports meshes, 3D Gaussian splats, and point clouds that can be imported into Unity, Unreal, Blender, and Isaac Sim, while rohanpaul_ai's overview centers the same shift as moving from frame prediction to persistent scene assets.
The official launch post adds one more concrete layer: the worlds are meant to be explored, with first-person and character-based navigation plus collision support, and WorldLens handles the real-time rendering path TencentHunyuan's launch post.
Four-stage pipeline
Tencent breaks the generation stack into four jobs instead of one monolithic model:
- HY-Pano 2.0, panorama generation from text or a single image.
- WorldNav, semantic trajectory planning with a spatial agent and navmesh.
- WorldStereo 2.0, keyframe-based world expansion with spatial memory.
- WorldMirror 2.0, final 3D reconstruction and composition into 3DGS assets.
That staged design shows up clearly in
, and rohanpaul_ai's architecture summary makes the practical claim Tencent cares about: better camera stability and more reusable scenes than single-view video generation.
WorldMirror 2.0
WorldMirror 2.0 is the part you can actually use today. The GitHub README describes it as a roughly 1.2B parameter feed-forward model that predicts depth, normals, camera parameters, point clouds, and 3DGS attributes in one pass from multi-view images or video, and the Hugging Face page hosts the released artifacts.
Tencent's own materials keep pointing back to reconstruction as the mature subsystem. rohanpaul_ai's benchmark summary says WorldStereo 2.0 leads Tencent's table on trajectory error, F1, and AUC, while rohanpaul_ai's paper roundup adds a runtime claim from the report: roughly 10 minutes per world on H20 GPUs for the full generation pipeline.
What's open now
The repo's release plan is more specific than the announcement copy. It lists technical report plus partial code on April 16, says WorldMirror 2.0 code and checkpoints are available now, and marks full world-generation inference, HY-Pano 2.0 weights, WorldNav code, and WorldStereo 2.0 inference as coming soon in the README.
That makes HY-World 2.0 an open release with an asterisk. The reconstruction path is public today through Hugging Face and GitHub, while Tencent is still scheduling an AMA on April 20 before the rest of the stack lands.