Seedance 2.0 supports 7-shot action prompt packs and acting tests in creator workflows
Creators published shot-timed action packs, crowd-cutaway formulas, emotion tests, and storyboard-driven Seedance 2.0 pipelines across LTX, Dreamina, PixPretty, and other tools. The posts turn Seedance from single-clip generation into repeatable scene design and performance workflows with documented prompts.
TL;DR
- techhalla's Seedance 2.0 action pack turned one prompt drop into seven reusable action setups, from aerial insertion to fire escape, and Volcengine's official overview says the model can mix text, images, audio, and video for clips up to 15 seconds.
- techhalla's crowd-cutaway prompt shows a more granular pattern, timing edits down to tenths of a second, while Segmind's workflow writeup says Seedance 2.0 supports 4 to 15 second clips, first and last frames, and omni-reference inputs.
- 0xInk_'s emotion test and 0xInk_'s follow-up pushed performance control into acting language, with the creator saying the result came from "4 acting techniques" rather than a pure camera trick.
- DrSadek_'s storyboard breakdown, Artedeingenio's character-sheet reply, and _OAK200's triptych system prompt all point to the same shift: creators are feeding Seedance boards, sheets, and multi-panel references so it can infer scene progression instead of animating a single still.
- CuriousRefuge's restoration workflow used Seedance 2.0 Omni as the first and third pass in a four-step remaster pipeline, which is a different lane from the action demos and probably the clearest sign that creators are treating Seedance like production infrastructure, not just a clip toy.
You can read ByteDance's official capability list, skim Dreamina's own pitch for director-style multi-shot control, and compare access points in Atlas Cloud's pricing breakdown. Then the creator evidence gets much more specific: techhalla's seven-shot pack is really a genre kit, CuriousRefuge's remaster thread uses Omni for footage cleanup, and _OAK200's triptych prompt tells the model to reconstruct the missing beats between three panels like an editor, not a frame interpolator.
7-shot action packs
The cleanest Seedance pattern in this batch is the prebuilt shot pack. techhalla's main thread framed it as seven action clips that do not all look like the same model template, and the later posts in the same thread break those into named scene types like Urban Detonation and Fire Sequence.
The useful part is the structure. The pack is already separated into reusable scene intents:
- Aerial insertion
- Canyon jump
- Storm crossing
- Mountain descent
- Urban detonation
- Rooftop pursuit
- Fire sequence
That is closer to a stunt library than a one-off prompt. AIandDesign's reply made the same point in one sentence, saying Seedance can take "6 shots" in one render and "ace it." Officially, Dreamina's Seedance guide describes the model as a system for coherent multi-shot video with control over motion, camera language, and rhythm, which matches what these packs are actually exploiting.
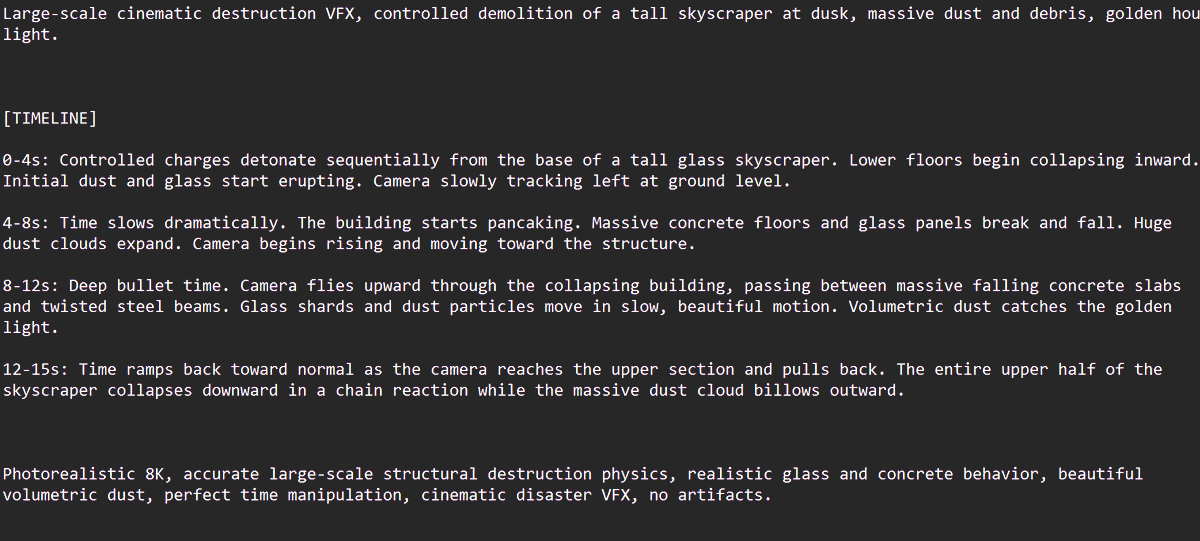
Timed crowd cutaways
Another recurring format is the shot-timed filler clip. techhalla's cutaway formula lays out a concert montage beat by beat, with shot windows like 0:00 to 0:01 and 0:01 to 0:01.7, then keeps going through a 14-second sequence.
The prompt is doing film grammar in plain text:
- exact time windows
- lens and movement cues like push-ins, whip cuts, and handheld passes
- crowd behavior, not just scenery
- a final payoff frame
- explicit negative space, like no stage performance shown directly
techhalla's later explosion breakdown uses the same recipe for VFX, dividing the clip into 0 to 4, 4 to 8, 8 to 12, and 12 to 15 second phases. The pattern is portable: define time segments, define camera behavior, define physical consequences. That lines up with Segmind's Seedance explainer, which highlights first and last frames, reference assets, and short fixed durations as the model's working envelope.
Emotion and acting prompts
The other standout result is performance control. 0xInk_'s emotion test drew far more engagement than the average workflow thread, and 0xInk_'s reply said the clip was driven by "a prompt with 4 acting techniques."
The phrasing matters. A lot of AI video prompting still overindexes on camera moves, lighting, and spectacle. Here the pitch is acting direction, and 0xInk_'s monster reel suggests the same creator has been iterating on emotion tests as a repeatable format.
That makes CharaspowerAI's GPT Image 2 plus Seedance combo and DrSadek_'s cyberpunk animation easier to read. The image models establish character look, but Seedance is getting used for expression, pacing, and motion performance. Volcengine's official post explicitly says reference video can carry over camera language, complex actions, and sound cues, which helps explain why creators are writing prompts more like direction notes than generic descriptors.
Storyboards and character sheets
The strongest workflow convergence is around preproduction assets. DrSadek_'s thread step says the sequence started with a Midjourney image, then a nine-panel storyboard in Nano Banana Pro, then a simple Seedance prompt to animate the board. Artedeingenio's reply adds the character-sheet rule directly, saying the sheets need to be uploaded so the model can use them as a visual guide through generation.
Across the evidence set, that workflow breaks into a few distinct methods:
- Storyboard first: DrSadek_ moves from concept image to nine-panel board to animation.
- Character sheet first: Artedeingenio's fairy-tale workflow and Artedeingenio's Cinderella workflow build Midjourney sheets, then animate them in Seedance.
- Triptych as narrative scaffold: _OAK200's system prompt tells Seedance to read top, middle, and bottom panels as sequential story beats and infer the missing transitions.
- Single board, multiple scenes: CuriousRefuge's consistency test says one well-defined character board can drive multiple characters, destinations, and art directions while keeping continuity intact.
This is where the creator use case starts looking less like text-to-video and more like previz. Dreamina's guide uses the phrase "director-style control," which sounds like marketing until you see prompts telling the model to preserve wardrobe, infer motivation, and end on a composed final frame.
Music-synced and reference-driven pipelines
Several posts treat Seedance as the motion layer inside a larger stack, not the whole stack. techhalla's Magnific tutorial step starts with character and scene images, techhalla's follow-up says to reuse generated videos as references to keep proportions and shot context stable, and the main thread says the result is a song-synced World Cup video.
The multi-tool patterns in evidence are surprisingly consistent:
- Image model for look, Seedance for motion: CharaspowerAI, Artedeingenio, awesome_visuals, and GlennHasABeard's reply all split still generation from animation.
- Audio-led sequencing: techhalla uses audio sync as the center of the video prompt.
- Timeline-led music video generation: bennash's Neural Frames post feeds a full shot timeline into another generator that now runs Seedance 2, then bennash's next post says the storyboard guidance can be pushed toward "Story."
- Reference recycling: techhalla's iteration note says previously generated videos can become new references for consistency.
That last point matters because it turns one good clip into training wheels for the next one. The workflow starts to compound.
Restoration and access surfaces
The most production-minded example in the set is not a fantasy scene at all. CuriousRefuge's thread uses Seedance 2.0 Omni to remaster old footage, then routes stills through GPT-Image 2, then sends the upgraded stills back into Seedance, then finishes in Topaz Astra.
The pipeline is explicit:
- Run the original clip through Seedance 2.0 Omni to stabilize and clean it.
- Export 3 to 8 stills.
- Upgrade those stills in GPT-Image 2.
- Feed the upgraded stills plus the cleaned clip back into Seedance to match the higher-quality style.
- Finish sharpening in Astra.
That workflow matches official product framing better than the meme clips do. Volcengine's article says Seedance 2.0 supports text, image, audio, and video inputs together, up to 9 images, 3 videos, 3 audio clips, and 15 seconds per generation. Atlas Cloud's pricing breakdown also captures why creators keep name-dropping different front ends: Dreamina for the global web UI, Jimeng in China, and a growing list of third-party surfaces and APIs. In this evidence set alone, creators mention LTX, Dreamina, Mitte, PixPretty, PixVerse, Magnific, Leonardo, OpenArt, SocialSight, Runway, and Hailuo as the place where the Seedance layer actually gets used.