Claude Opus 4.8 ships with 69.2% SWE-Bench Pro and 2.5x Fast mode
Anthropic released Claude Opus 4.8 across Claude, the API, and major clouds with higher coding scores and a cheaper 2.5x-speed Fast mode. Use it for coding workloads that want better benchmark performance without a price increase over 4.7.
TL;DR
- Anthropic shipped Claude Opus 4.8 on May 28, with the same list price as 4.7 and day-one availability across Claude, the platform, and major clouds, according to claudeai's launch post and claudeai's availability post.
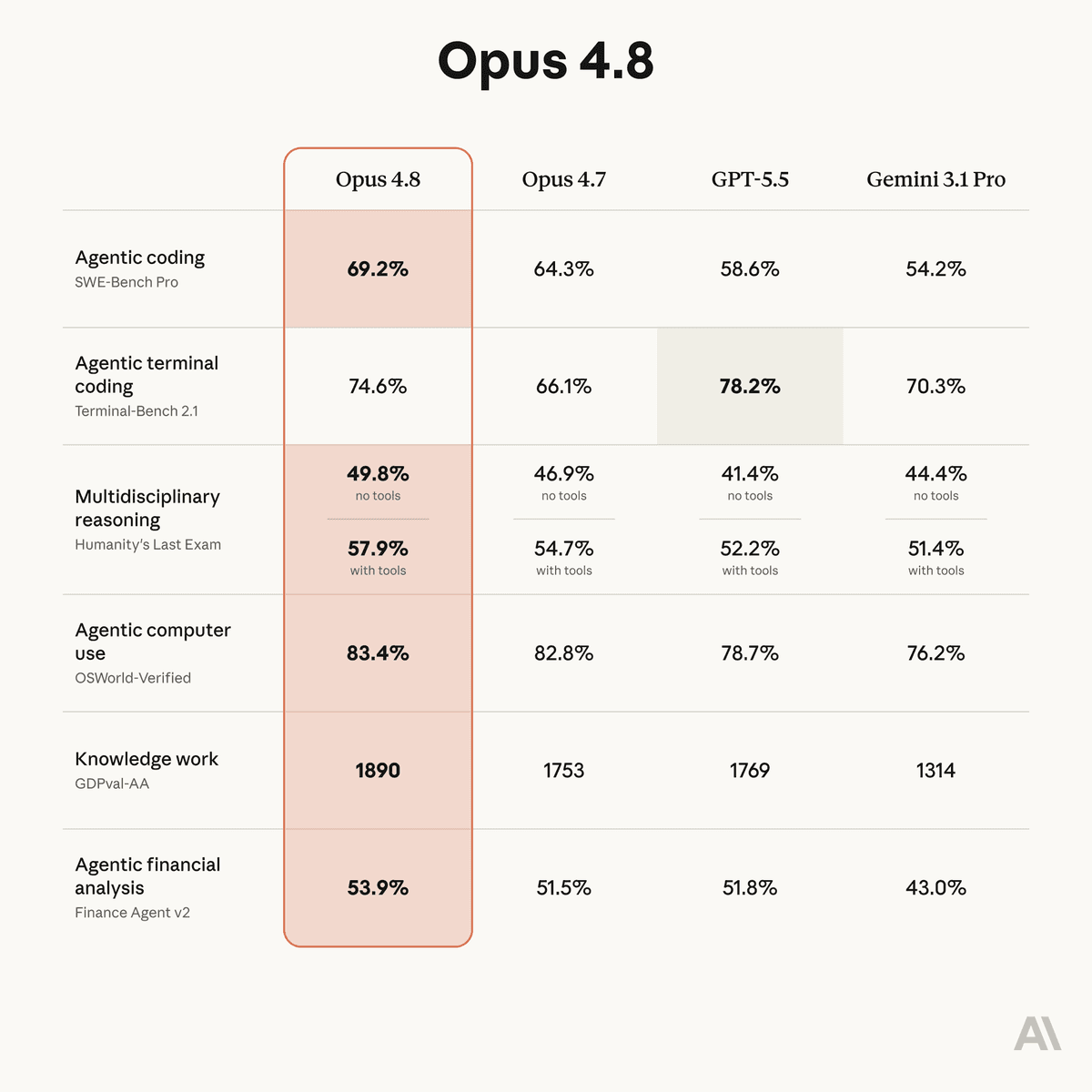
- On Anthropic's headline coding benchmark, Opus 4.8 moved SWE-Bench Pro from 64.3% to 69.2%, a +4.9 point jump that testingcatalog's benchmark note and Boris Cherny's post both called out.
- Fast mode is the buried launch detail: kimmonismus highlighted Anthropic's claim of roughly 2.5x speed, while scaling01's cost comparison shows Fast dropped from a 6x premium on 4.7 to 2x on 4.8.
- The bigger workflow change is in Claude Code, where Yuchenj_UW's quote from the release blog says Dynamic Workflows can plan work, run hundreds of parallel subagents, and verify outputs before reporting back.
- Third-party results were strong but not cleanly one-way: Artificial Analysis put Opus 4.8 at the top of its index, while theo's CursorBench note said it was slightly worse than 4.7 within margin of error.
Anthropic's own launch copy called Opus 4.8 a "modest but tangible improvement", which is unusually blunt for a flagship model release. You can read Simon Willison's notes, compare third-party scores on Artificial Analysis, and trace the same-day Claude Code rollout in the official changelog.
What shipped
Anthropic framed Opus 4.8 as a sharper Opus 4.7, not a reset. The launch post says it improves judgment, honesty about progress, and long independent runs, and Boris Cherny, Claude Code lead at Anthropic, summarized the model the same way: stronger coding plus fewer premature claims of success.
The concrete ship list was broader than the benchmark table:
- Same input and output pricing as 4.7, per claudeai's launch post and Artificial Analysis.
- Available on Claude, the Claude Platform, and major clouds on day one, per claudeai's availability post.
- Effort controls in Claude with Low, Medium, High, Extra, and Max, according to testingcatalog's rollout note.
- Fast mode on Opus 4.8 at roughly 2.5x speed, per kimmonismus and OpenRouter.
- Dynamic Workflows in Claude Code research preview, where Claude can orchestrate hundreds of parallel subagents, according to Yuchenj_UW's quote from the release blog.
Benchmarks that moved
First-party
- SWE-Bench Pro: 64.3% → 69.2%, +4.9 points, per testingcatalog's benchmark note.
- Anthropic says the model is around four times less likely to let flaws in its own code pass unremarked, according to OpenRouter's launch summary and Simon Willison's write-up.
Third-party evaluators
- GDPval-AA Elo: 1753 → 1890, +137 points, per ArtificialAnlys on GDPval-AA.
- Artificial Analysis Intelligence Index: 57.3 → 61.4, +4.1 points, per Artificial Analysis.
- Vals Index: undisclosed prior score → 70.2%, new high, per ValsAI's results post.
- Vals Multimodal: undisclosed prior score → 70.7%, new high, per ValsAI's results post.
- APEX-SWE Pass@1: prior score not stated → 45.3%, nearly +4 points, per scaling01 relaying Mercor's APEX-SWE result.
- FrontierSWE: prior score not stated → #1 ranking, per scaling01 on FrontierSWE.
- AutomationBench: prior score not stated → #1 ranking, per scaling01 on AutomationBench.
Customer-reported
- Box's industrial goods reporting task: 77% → 87%, +10 points, per Aaron Levie's Box testing thread.
- Box's consumer products launch evaluation: 84% → 90%, +6 points, per Aaron Levie's Box testing thread.
Artificial Analysis added the most useful qualifier. Its follow-up post says Opus 4.8 used 15% fewer turns and 35% fewer output tokens than 4.7 on GDPval-AA, but still needed about 30% more turns than GPT-5.5.
Where it regressed
Not every evaluator saw a clean win.
- theo's CursorBench note says Opus 4.8 was more efficient, but slightly worse than 4.7 within margin of error.
- Jerry Liu, founder of LlamaIndex, said ParseBench found small gains on tables, semantic formatting, and layout, but worse content faithfulness and related document-understanding metrics.
- bridgemindai relaying BridgeBench said early Lava Lamp results did not show a huge improvement over 4.7.
- TheRealAdamG relaying Cline said Terminal-Bench 2.1 still had Opus 4.8 trailing GPT-5.5 by 3.6%.
- scaling01's RuneScape Bench post placed Opus 4.8 Max in fourth, with GPT-5.5-xhigh back in first.
Those misses line up with Anthropic's own modest framing in the launch post. Simon Willison quoted the same line because it was rare to see a frontier release pitched as incremental instead of epochal in his notes.
Fast mode
Fast mode was the easiest launch detail to miss and probably the most operationally relevant one.
The change is simple:
- Opus 4.8 Fast runs at roughly 2.5x the speed of standard Opus 4.8, per kimmonismus and OpenRouter.
- The premium dropped to 2x standard cost, per scaling01's comparison and teortaxesTex.
- On Opus 4.7, the same 2.5x speedup cost 6x, according to scaling01's comparison.
That price cut changed the launch conversation fast. teortaxesTex called it a new point on the Pareto frontier, while nummanali still complained that Fast burns through Claude credits quickly in practice.
Dynamic Workflows
Claude Code got its own parallel story. Anthropic's release copy, as quoted by Yuchenj_UW, says Dynamic Workflows can plan a job, run hundreds of subagents in one session, then verify the result before returning control.
The same-day Claude Code 2.1.154 changelog added more detail:
- Dynamic Workflows orchestrate tens to hundreds of background agents, per ClaudeCodeLog's 2.1.154 highlights.
- Hard tasks default to high effort, exposed in the CLI as
/effort xhigh, per ClaudeCodeLog's 2.1.154 highlights. - A new
/workflowscommand lets users inspect running jobs, according to ClaudeCodeLog's detailed changelog. - Auto mode's classifier was updated to better detect bulk repo exfiltration in automated runs, per ClaudeCodeLog's 2.1.154 highlights and ClaudeCodeLog's detailed changelog.
Hands-on posts show the feature getting marketed as "ultracode." daniel_mac8 described Claude autonomously writing an orchestration script and spawning an agent swarm, while WesRoth used it to build a town simulation with an autonomous economy and traffic system.
Vibe Check
Early hands-on reports clustered around two themes: longer autonomous runs and less fake confidence.
- Ethan Mollick said Opus 4.8 drafted an academic paper from hundreds of de-identified research files, then corrected a major issue after GPT-5.5 reviewed it.
- In a follow-up, Mollick's second post said the model handled hypothesis formation, data cleaning, reference research, robustness checks, and LaTeX-style drafting in one run.
- Jeremy Howard said 4.8 felt more cooperative than 4.7 and less over-agentic, stopping for input where 4.7 and GPT-5.5 would push ahead.
- theo said the new ultracode path could exhaust a $100 Claude tier in a single prompt.
- benhylak highlighted how long and unusual Opus 4.8 reasoning traces looked, and haider1 argued the model appeared to spend more tokens than prior Opus versions at similar effort levels.
That matches the split in the benchmark chatter. Artificial Analysis saw efficiency gains versus 4.7 on some workloads, while sarahwooders relaying Charles Packer said it was still far less token-efficient than GPT-5.5.
Where it shows up
The ecosystem rollout was immediate and broad.
- OpenRouter shipped both standard and Fast mode on day one, per OpenRouter's availability post.
- Vercel added the
anthropic/claude-opus-4.8slug to AI Gateway, according to vercel_dev's AI Gateway post and the Vercel changelog. - Perplexity made it available to Max subscribers on Perplexity and Computer, per perplexity_ai.
- Cognition added it to Windsurf and Devin CLI, according to cognition.
- v0 exposed Opus 4.8 on launch day, per v0.
- GitHub rolled it out to
@code, Copilot CLI, and Copilot app developers, according to pierceboggan. - Letta Code added support and reported better token efficiency with comparable context management to 4.7, per Letta_AI.
- Box said Opus 4.8 would roll out shortly to Box AI agents after internal testing, per Aaron Levie's Box testing thread.
This was also a classic inference-layer land grab. testingcatalog flagged same-day availability on AI/ML API, rork pushed it into Rork, and charmcli said Crush got it without a client update.
Claude Code hotfix
Six hours after the big Claude Code rollout, Anthropic pushed 2.1.156 to fix an Opus 4.8-specific bug.
According to ClaudeCodeLog's 2.1.156 changelog post, the issue modified thinking blocks and caused API errors. The official changelog entry confirms the same fix, which is a useful reminder that this launch was not just a model swap. It changed the surrounding harness fast enough to need a same-night patch.