lift-pdf releases 9B extractor with 90.2% accuracy and 9.5s p50
lift-pdf released an open-source 9B model for schema-constrained document extraction, with code, pip install, playground access, and a 90.2% score on the team's 225-document bench. It matters because the model claims near-Gemini 3.5 Flash accuracy at 9.5s p50, though coverage is still skewed toward Latin-language docs and commercial-use limits remain.
TL;DR
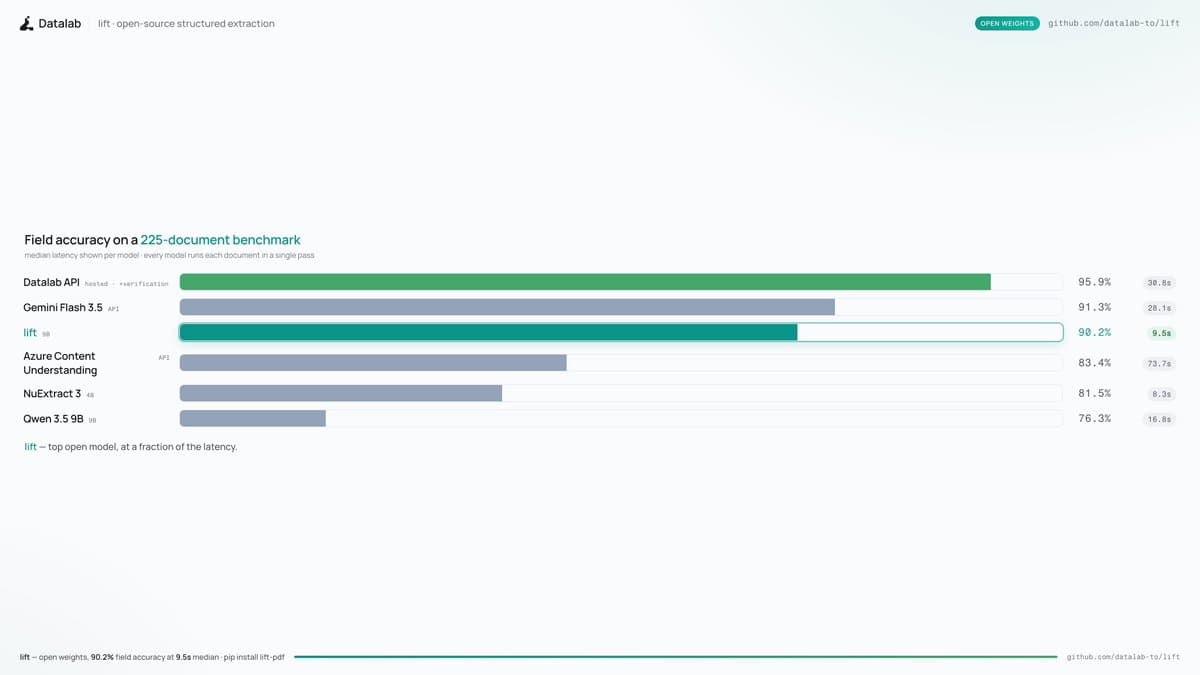
- VikParuchuri's launch post says lift-pdf open sourced a 9B document extraction model that hits 90.2% on the team's benchmark, versus 91.3% for Gemini 3.5 Flash.
- Installation is already packaged as
pip install lift-pdf, with VikParuchuri's install thread linking the model, code, and blog post. - Benchmark details from VikParuchuri's benchmark note put the eval at 225 documents across several categories, spanning 6 to 64 pages.
- According to VikParuchuri's Azure comparison reply, lift posted 9.5s p50 latency against Azure Content Understanding's 73.7s on the same comparison he called the closest flexible-schema competitor.
- Caveats showed up quickly in replies: VikParuchuri's commercial-use reply says commercial use is allowed only with limits, while VikParuchuri's language-coverage reply says the benchmark is mostly skewed toward Latin-language documents.
You can grab the model, browse the code, and read the blog post. There is also a hosted playground path with $10 free credit, and the launch video already shows the basic invoice-to-JSON flow.
What shipped
The release is narrow and useful: a schema-constrained extractor, not a general document parser. In VikParuchuri's LiteParse clarification, he draws that line explicitly, saying LiteParse turns documents into markdown while this model extracts specific fields into a JSON schema.
The shipping surface is simple:
- Open-source 9B model, per VikParuchuri's launch post
- Python package via
pip install lift-pdf, per VikParuchuri's install thread - Hosted playground access with free credit, per VikParuchuri's playground note
- JSON-schema extraction path inside the playground's "Extract" mode, per VikParuchuri's product reply
- Image support, according to VikParuchuri's image-support reply
Benchmarks and latency
The main claim is near-frontier extraction accuracy without frontier-model latency. VikParuchuri's launch post puts the model at 90.2%, 1.1 points behind Gemini 3.5 Flash, and 8.7 points ahead of NuExtract3.
The benchmark setup in VikParuchuri's benchmark note is 225 documents across several categories, with document lengths from 6 to 64 pages and a focus on harder extraction cases. The closest like-for-like competitor in his replies is Azure Content Understanding, which VikParuchuri's Azure comparison reply lists at 83.4% accuracy and 73.7s p50 latency versus lift at 90.2% and 9.5s p50.
That speed claim is the interesting bit for engineering teams. A lot of document AI numbers look good until the pipeline turns into an async job queue.
Turbo mode
The broader product story is not just the open model. lift also shipped a turbo extraction mode through its API, and VikParuchuri's API reply says you enable it with extraction_mode: turbo.
The posted turbo numbers are:
- 4.5s p50 and 7s p90 across 1 to 30 page documents, per VikParuchuri's turbo launch post
- 4.67s p50, 7.0s p90, 17.05s p99 in a later latency readout from VikParuchuri's turbo metrics thread
- 89.5% field accuracy versus Azure's 83.4%, per VikParuchuri's turbo metrics thread
- $6 per 1,000 pages versus Azure's $33, per VikParuchuri's turbo metrics thread
VikParuchuri's playground note adds that turbo is the fast path, while fast and balanced modes trade speed for higher accuracy, citations, and verification.
Limits and gaps
The launch thread also surfaced the weak spots faster than the headline post did.
- Commercial use is allowed, but with license limits, according to VikParuchuri's commercial-use reply
- Long-document support still needs work, per VikParuchuri's long-doc reply
- Language coverage is still mostly Latin-script, according to VikParuchuri's language-coverage reply
- Indic-script coverage is thin enough that VikParuchuri's Indic-script reply says the benchmark does not include much of it
- Schema edge cases can still fail, and VikParuchuri's schema-edge-case reply cites conflicting fields as one example
That makes this release feel more like a strong extraction specialist than a universal document stack. Even in the replies, VikParuchuri's model-backend reply says he is not fully sure what models some competing systems use, which is a good reminder that a lot of document-AI comparisons are still messy once you leave the benchmark table.