Sakana Fugu launches one-API orchestration with Fable benchmark claims
Sakana AI launched Fugu and Fugu Ultra as OpenAI-compatible orchestration models that route, verify, and synthesize across multiple models. The release matters because Sakana is selling multi-agent coordination as a single endpoint, but it has not fully disclosed model mix or pass-through costs.
TL;DR
- Sakana AI shipped SakanaAILabs' launch post and its architecture thread around a new product frame: a single OpenAI-compatible endpoint that hides a multi-agent, multi-model system behind one model slug.
- According to SakanaAILabs' product thread, Fugu is itself an LLM that can call other models, including recursive calls to itself, then handle selection, delegation, verification, and synthesis automatically.
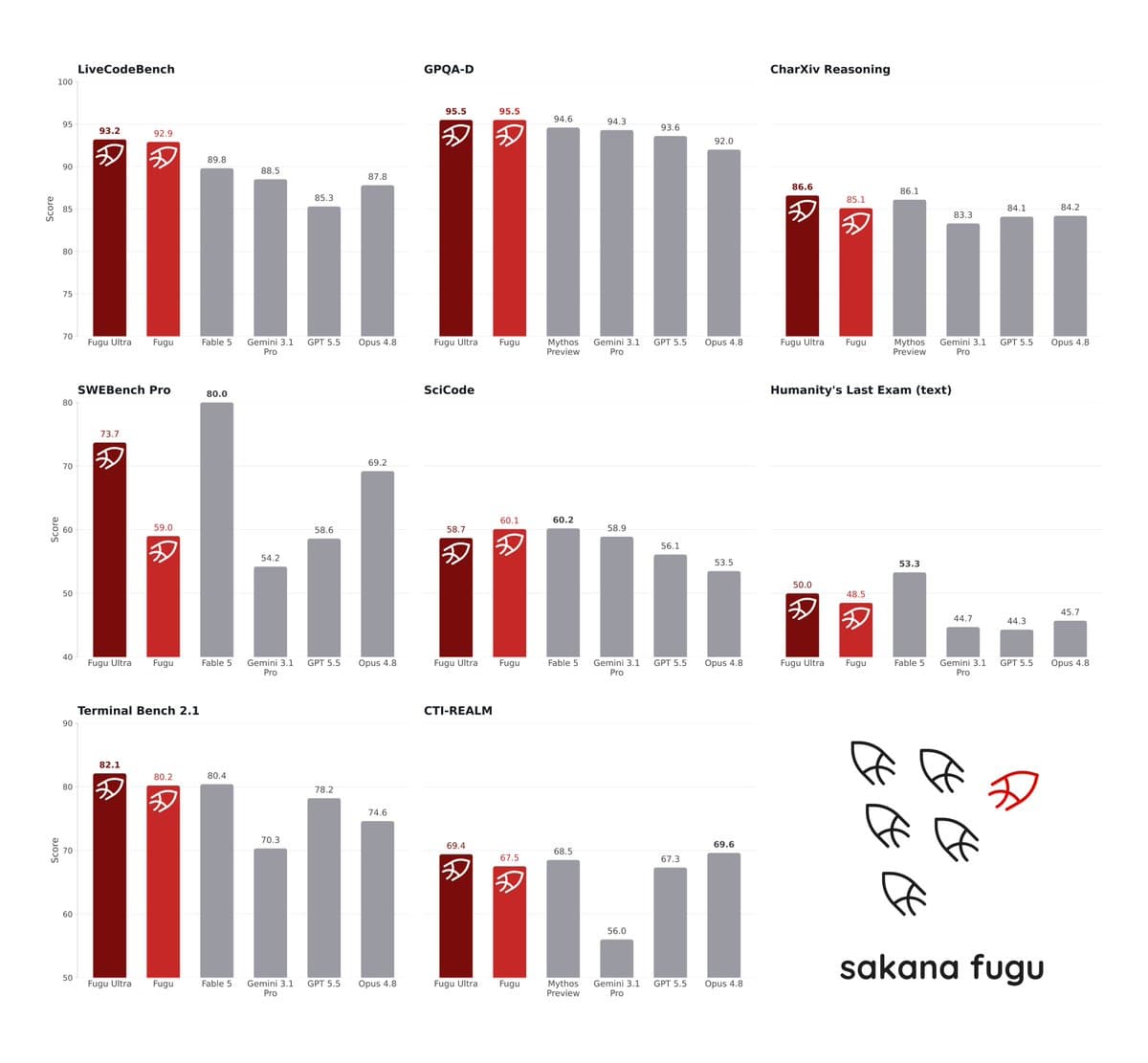
- The benchmark chart in Stewart Butterfield's repost with Sakana's graphic shows Fugu Ultra winning or tying several evals, but trailing Fable 5 on SWE-Bench Pro and Humanity's Last Exam, and trailing Opus 4.8 on CTI-REALM.
- Sakana's core pitch in its blog thread and Hardmaru's launch thread is not just capability, but sovereignty: an orchestration layer that can swap underlying agents when access to a single frontier model disappears.
- Critics including eliebakouch's thread and his pricing question focused on what the launch left fuzzy, especially the closed versus open model mix behind benchmark runs and how pass-through costs work when multiple agents fire.
You can read Sakana's launch thread through the linked blog, inspect the system diagram and product split in Sakana's architecture post, and see that the pricing questions got sharper once a screenshot of the pay-as-you-go page started circulating. The odd part is that Sakana pitched Fugu as a hedge against vendor dependence while community replies immediately asked how much of the benchmark story still depends on closed vendor APIs.
One endpoint
Sakana is packaging orchestration as a model, not as a developer-built harness. The launch post describes Fugu as a "full multi-agent orchestration system accessible via a single model API," while the follow-up thread says both Fugu and Fugu Ultra sit behind one OpenAI-compatible interface.
The split is simple in Sakana's own framing:
- Fugu: lower-latency default for coding tools, chatbots, and interactive services, per SakanaAILabs' product description.
- Fugu Ultra: deeper orchestration for hard multi-step work like AI research, cybersecurity analysis, and patent investigations, per the same thread.
- Compliance control: developers can opt specific agents out of the pool for data compliance, according to SakanaAILabs.
That last point is one of the more practical reveals in the thread. It implies the product surface is not only "best model wins," but "best allowed model wins," which matters if the agent pool spans providers with different data handling rules.
Delegation loop
The technical claim is that Fugu is not only a router. Sakana says in its architecture thread that Fugu is itself an LLM trained to call various LLMs in an agent pool, including recursive calls to itself.
The loop Sakana describes has four steps:
- Model selection
- Delegation
- Verification
- Synthesis
That sounds closer to a learned manager than a static rules engine. Kyle Jeong's reply asked the obvious question, "isn’t this just really good model router then?" Sakana's own wording pushes back by claiming the coordinator can sometimes solve tasks directly, then escalate to a team only when needed, per the product thread.
Box CEO Aaron Levie made the same distinction from the outside. In Aaron Levie's post, he noted that many applied AI products already use this kind of orchestration inside agent harnesses, but Sakana is exposing the pattern as something any developer can hit through a single model API.
Benchmark spread
The benchmark card attached to Aaron Levie's post and repeated in Rohan Paul's summary is broad enough to matter because it is not only coding or only reasoning.
Across the eight charts visible in the image:
- LiveCodeBench: Fugu Ultra 93.2, ahead of Fable 5 at 89.8, per the benchmark image.
- GPQA-D: Fugu Ultra and Fugu both at 95.5, ahead of Mythos Preview at 94.6, per the image.
- CharXiv Reasoning: Fugu Ultra 86.6, slightly ahead of Mythos Preview at 86.1, per the image.
- SWE-Bench Pro: Fugu Ultra 73.7, behind Fable 5 at 80.0, per the image.
- SciCode: base Fugu at 60.1 edges Fugu Ultra at 58.7 and Fable 5 at 60.2 is effectively tied, per Rohan Paul's summary of the chart.
- Humanity's Last Exam, text: Fugu Ultra 50.0, behind Fable 5 at 53.3, per the image.
- Terminal Bench 2.1: Fugu Ultra 82.1, ahead of Fable 5 at 80.4, per the image.
- CTI-REALM: Fugu Ultra 69.4, behind Opus 4.8 at 69.6, per the image.
So the launch claim in SakanaAILabs' benchmark thread, "stands shoulder-to-shoulder," is directionally supported by its own chart, but the chart is not a clean sweep. The interesting part is the shape: orchestration seems strongest on mixed engineering and reasoning tasks, not uniformly best on every benchmark Sakana chose to show.
Sovereignty pitch
Sakana's most opinionated claim is geopolitical, not architectural. In its thread and Hardmaru's longer launch post, the company argues that orchestration has become a hedge against export controls and single-vendor dependence.
That pitch has three pieces:
- access to frontier APIs can disappear quickly, according to SakanaAILabs
- a swappable agent pool reduces dependence on any one provider, according to Hardmaru
- the orchestration layer becomes the durable asset, because it can route around model availability changes, according to the company thread
The pushback landed immediately. eliebakouch's criticism argued that calling this "without the risk of export controls" is misleading if benchmark performance still relies partly on closed source model APIs, and his follow-up question asked Sakana to disclose what percentage of each benchmark run came from which models.
That is the sharpest unresolved launch question in the evidence pool: how much of Fugu's performance comes from Sakana's learned coordination, and how much comes from access to whichever frontier models sit behind the curtain.
Pricing page
The pricing screenshot attached to eliebakouch's question adds one concrete detail that the launch tweets did not. The pay-as-you-go page says that when one Fugu agent is active, "you pay only the standard rate for that specific underlying model," and when multiple agents are active, Sakana "never stack[s] model fees" and instead charges a single rate based on the top-tier model involved.
The same screenshot shows fixed pricing for fugu-ultra-20260615:
- Input: $5, or $10 above 272K context, per the pricing screenshot
- Output: $30, or $45 above 272K context, per the pricing screenshot
- Cached input: $0.50, or $1.00 above 272K context, per the pricing screenshot
Those numbers answered one question and opened another. The reply thread around the screenshot asked whether a run that fans out across Opus, DeepSeek, and Kimi is billed only at the top-tier rate or also smuggles in the underlying providers' token economics. The launch material in this evidence set does not resolve that ambiguity.