Sentence Transformers releases v5.4 with multimodal embeddings and reranking
Sentence Transformers v5.4 adds one encode API for text, image, audio, and video, plus multimodal reranking and a modular CrossEncoder stack. It also flattens Flash Attention 2 inputs for text workloads, reducing padding waste and VRAM use.
TL;DR
- Tom Aarsen's release thread and the Hugging Face blog post introduced Sentence Transformers v5.4 as a multimodal upgrade for both embeddings and reranking.
- According to Aarsen's API example,
SentenceTransformer.encode()now handles text, images, audio, and video, and the same release adds cross-modal similarity for mixed retrieval workloads. - Aarsen's reranking note and the v5.4.0 release notes say
CrossEncodernow supports multimodal reranking, including image-query-to-text-document ranking. - Aarsen's CrossEncoder thread says the reranker stack is now modular, which is what enabled CausalLM-based generative rerankers through a new
LogitScoremodule. - Aarsen's Flash Attention 2 update says text-only batches now get automatic input flattening, so padded tokens are skipped and variable-length workloads use less compute and VRAM.
You can jump straight to the multimodal walkthrough, the full v5.4.0 release notes, and Aarsen's Router example if you care about mixing separate encoders by modality. The reranking update quietly makes image-to-text ranking a first-class path, while the final thread post frames this release as groundwork for late-interaction models in the next major version.
One encode API for four modalities
The biggest change is boring in the best way: multimodal support lands in the existing SentenceTransformer interface instead of a parallel stack. The Hugging Face post says v5.4 can encode and compare text, images, audio, and video with the same familiar API.
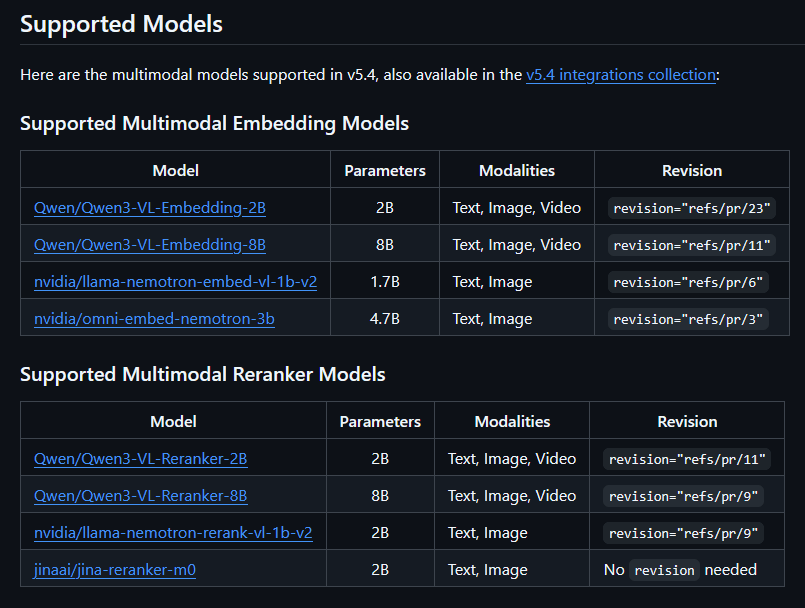
That includes mixed inputs, not just side-by-side modality support. Aarsen's example says you can encode any supported modality with .encode() and compare outputs with .similarity(), with models like Qwen3-VL-Embedding-2B working out of the box.
Router
Multimodal support does not force one monolithic model. Aarsen's Router thread says the updated Router module can detect modality and send each input to a separate encoder, which matters if you want to stitch together distinct text, image, audio, or video back ends inside one pipeline.
The release notes describe v5.4 as first-class multimodal support, and Router is the practical escape hatch for teams that already have modality-specific models they do not want to replace.
Multimodal reranking
v5.4 extends the multimodal story to rerankers, not just embedding models. Aarsen's thread says CrossEncoder can now score text documents against an image query, or any other modality pairing the model supports, with jinaai/jina-reranker-m0 called out as a ready-to-run example.
That turns Sentence Transformers into a more complete retrieval stack. The blog post frames multimodal rerankers as models that score the relevance of mixed-modality pairs, which is the missing piece after cross-modal embedding retrieval.
Modular CrossEncoder
The structural change underneath reranking is that CrossEncoder is now a torch.nn.Sequential of composable modules. Aarsen's thread says that refactor unlocked generative rerankers based on causal LMs through a new LogitScore module.
Aarsen names mxbai-rerank-v2 and Qwen3 rerankers as models that now work without custom code. The release notes also mention a migration guide for updated import paths and renamed parameters, while saying existing code should still run with warnings rather than hard breaks.
Flash Attention 2 input flattening
The performance tweak in this release targets text-only inputs. Aarsen's thread says Flash Attention 2 now concatenates sequences into one flat tensor and skips padding automatically, which removes wasted attention work on padded tokens.
The release notes tie the gain to batches with uneven sequence lengths. That is a low-level optimization, but it is the kind engineers actually feel in throughput and VRAM when embedding long, messy corpora.
Late-interaction groundwork
The last interesting note is about what v5.4 is setting up next. Aarsen's final post says the release lays groundwork for easier support of late-interaction models, both text-only and multimodal, in the next major version.
That same post includes the extras-based install target, sentence-transformers[image,audio,video]==5.4.0, while the release notes pointer links to the full changelog for training, inference, and optional dependency combinations.