Claude Code /goal tests compare 8.4k-token fast runs with 38.2k-token verified runs
New Claude Code and Codex tests showed open-ended /goal runs drifting or stopping too early, while planning-first and verifier loops forced rechecks before completion. The more reliable setup improves long build workflows, but it costs more turns and tokens.
TL;DR
- In Aakash Gupta's 38.2k-token verifier-loop example, the same research task jumped from 8.4k tokens in a one-turn run to 38.2k tokens in a seven-turn
/goalrun because a second model rejected missing source URLs before the agent could stop. - Aakash Gupta's failure report found three repeatable ways to burn turns in
/goal: vague finish lines, impossible dependencies, and compound tasks that hide multiple completion criteria. - According to Aakash Gupta's /goal walkthrough, the checker only reads the transcript, while Boris Cherny's reply frames the bigger pattern as model plus guardrails plus verifier loop.
- Planning changes the economics: AIandDesign's Fable port story says a detailed implementation plan let Opus nearly one-shot an iOS rewrite, and their follow-up claims even Sonnet handled early steps cleanly because the plan was so specific.
- Open-ended autonomy is still shaky. Peter Yang's Codex post described a two-hour
/goalrun that still needed constant steering, while k_grajeda's artsy-goal demo showed that an undefined finish line can loop indefinitely.
You can read Aakash Gupta's linked /goal guide, compare it with the more detailed PM playbook, and see how fast community patterns formed around verifier loops, plan-first runs, and even cross-model councils in Shann Holmberg's setup. The funny part surfaced fast too: Peter Yang's joke post about asking /goal to "build me an amazing game" landed because people were already watching vague goals spiral.
Verifier loops
The core mechanic is simple in Gupta's walkthrough: one model does the work, a second model checks whether the printed evidence matches a concrete finish line, and the run keeps looping until that checker approves.
Gupta's side-by-side pricing-task test makes the trade-off concrete:
- Fast run: 1 turn, 8.4k tokens, looked complete, but shipped five pricing claims with zero verified sources.
- Verified run: 7 turns, 38.2k tokens, because a second model rejected the output when one tool had no source URL.
- Result: 4.5x more tokens for an output where all five source links were verified.
That separation is the whole trick in Gupta's release-notes test too. The worker never decides that it is done.
Failure modes
Gupta's testing thread breaks the common failure cases into three buckets:
- Vague quality bar: "production-ready" kept looping because the checker could not tell half-done from done.
- Impossible dependency: a broken Stripe staging webhook ate 40 turns retrying a task that could not succeed.
- Compound goal: bundling auth, OAuth, tests, and docs into one instruction created multiple hidden finish lines.
The deeper limitation in that same thread is that the judge only reads transcript text. If the proof never gets printed to screen, the loop can either approve garbage or never stop.
That maps cleanly onto k_grajeda's artsy-goal example, where an agent kept running because "artsy" never became a measurable stop condition, and onto Peter Yang's report, where a long Codex run kept making wrong assumptions and still needed human steering.
Planning first
The strongest positive pattern in the evidence is not more autonomy, it is more planning.
AIandDesign's porting example says Fable generated a detailed migration plan for moving a PWA to a native Swift iOS app, and Opus then executed that plan closely enough that the app was already in TestFlight. In the follow-up, the same author says Sonnet handled the early steps "completely flawlessly" because the plan had already narrowed the task.
That lines up with Peter Yang's question about whether a drifting /goal run should have started with a detailed plan first. It also lines up with Gupta's overnight runs, which argues that defining three precise finish lines took longer than any individual prompt.
The shared pattern across those posts looks like this:
- Write the finish line before the run starts.
- Split multi-part work into separate goals.
- Print the proof into the transcript so the checker can see it.
- Add a blocked-state clause so the loop can quit honestly.
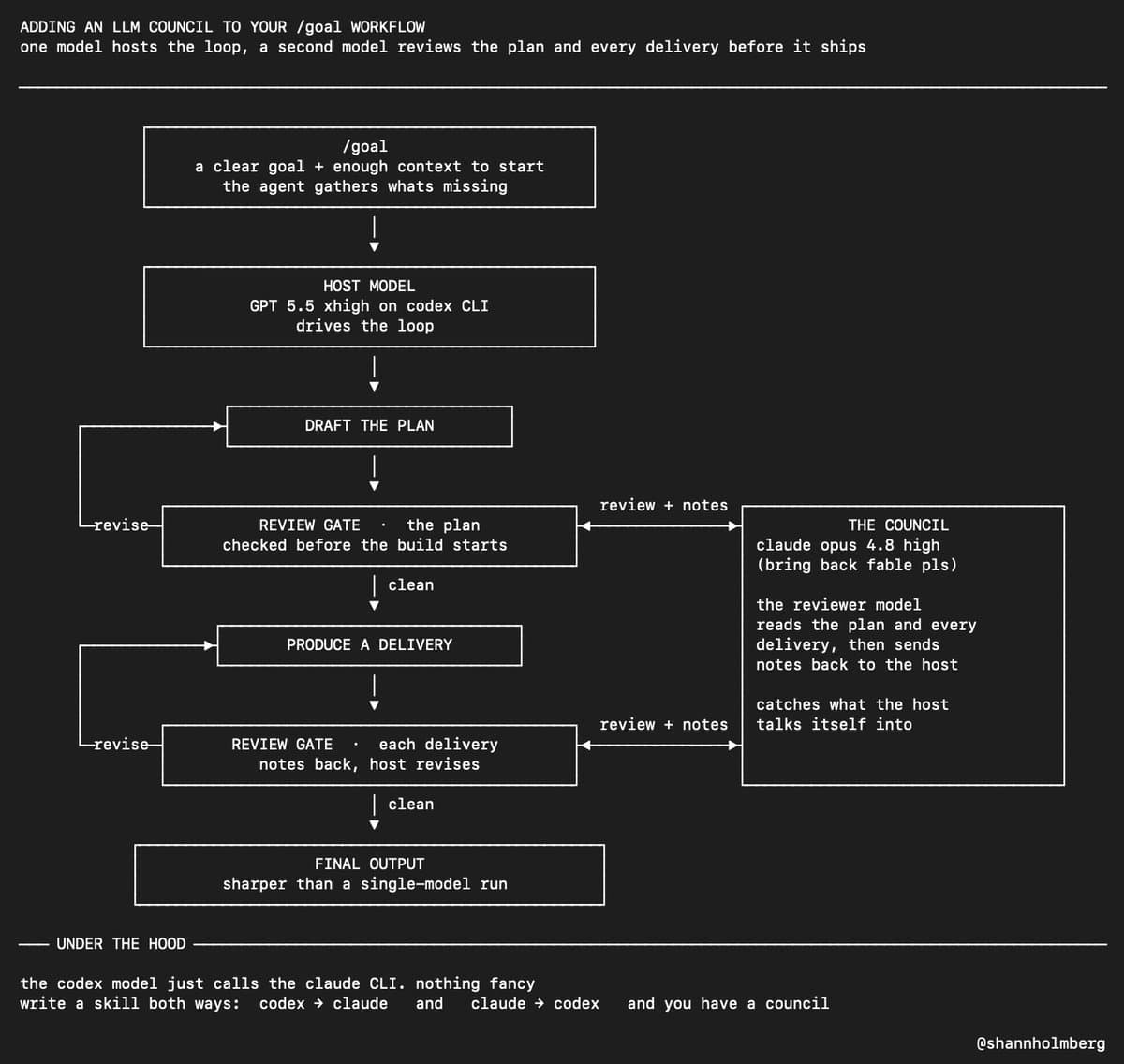
Model councils
A second pattern emerged fast: people are already turning verifier loops into multi-model systems.
In Shann Holmberg's post, GPT 5.5 xhigh hosted the loop in Codex CLI while Claude Opus 4.8 high reviewed both the plan and each delivery. Holmberg says the implementation is just two skills that let Codex call Claude and Claude call Codex.
Boris Cherny, Claude Code lead at Anthropic, describes the same direction more generally: run Claude Code plus an advanced model plus a verifier in a loop, then remove bottlenecks. Everlier's reply adds a smaller implementation note, saying programmatic orchestration helps when long contexts get fuzzy because control flow returns to code.
There is even a creative version in rainisto's BeatBandit thread, where Fable used MCP plus separate reviewer agents to score screenplay quality, inspect code, and feed the system back into another pass.
Overnight runs
Gupta's overnight account adds the cleanest operating picture in the whole batch: three terminal windows, three repos, three /goal commands, each with a different finish line. One run produced a PRD-based diff, one triaged a 14-issue bug backlog with tested fixes, and one drafted release notes while excluding 34 internal commits for stated reasons.
The price tag stayed ugly. That same post says each run burned 10 to 20 times the tokens of a single prompt, while the release-notes example shows why people are still paying it: the slow run matched prior format, listed nine included changes, skipped 14, and logged a one-line reason for every skip.
That is a different product than the one-turn draft. It is closer to a paper trail.