Artificial Analysis launches AA-Briefcase with Claude Fable 5 at 1587 Elo
Artificial Analysis launched AA-Briefcase, a benchmark for multi-week knowledge-work projects with thousands of source files, and Claude Fable 5 leads at 1587 Elo. The first results show a wide cost spread, so teams should compare both quality and task cost before choosing a model.
TL;DR
- Artificial Analysis introduced AA-Briefcase as a benchmark for multi-week knowledge-work projects with linked tasks, thousands of source files, and mixed grading for correctness, analysis, and presentation, according to Artificial Analysis's launch thread.
- In the first public leaderboard, Artificial Analysis's results thread put Claude Fable 5 at 1587 Elo, ahead of Claude Opus 4.8 at 1356, while GLM-5.2 was the closest non-Anthropic model at 1266.
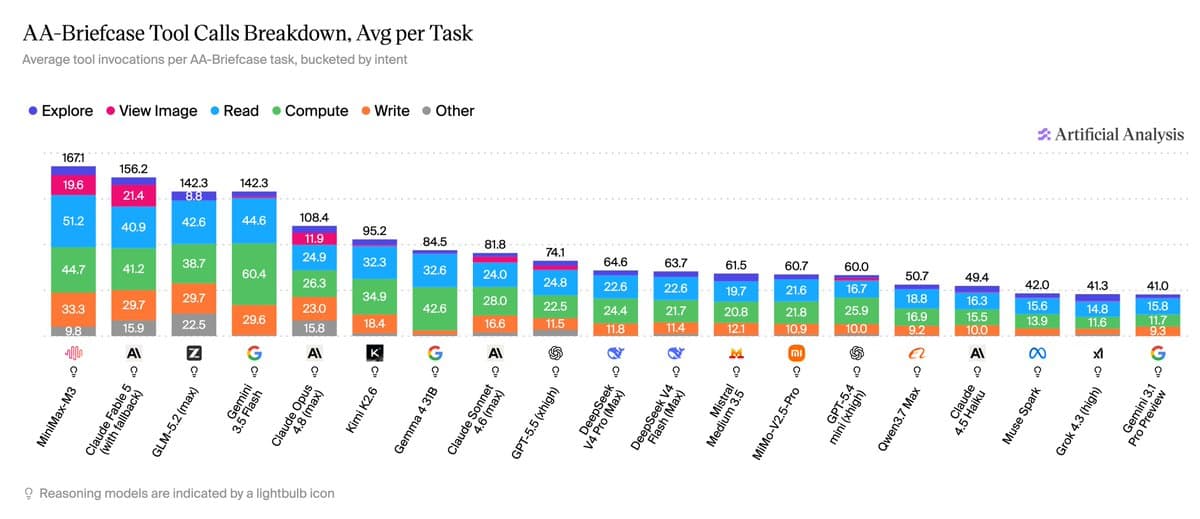
- The benchmark's sharpest result is how little headroom models still have: Artificial Analysis's difficulty breakdown said Fable 5 achieved a perfect score on only 3% of tasks, and 31 of 91 tasks saw no model clear 50%.
- Quality and cost split hard on this eval, with Artificial Analysis's cost summary putting Fable 5 above $31 per task, Opus 4.8 at $10.40, GPT-5.5 at $3.68, and GLM-5.2 at $2.40.
- The launch also reopened the usual benchmark fight, because Ethan Mollick's reaction called AA-Briefcase a strong upgrade with private holdout tests, while Mollick's earlier criticism said Artificial Analysis still has to answer harder questions about validity and human baselines.
You can read the launch article, inspect the full results, and the public-lite version lives in Artificial Analysis's launch thread via Hugging Face. One oddity in the first chart is that Artificial Analysis's launch thread says Claude Fable 5 was evaluated before it became unavailable. Another is that Artificial Analysis's tool-use note ties strong scores to repeated image inspection, which is not the usual headline for a knowledge-work benchmark.
AA-Briefcase
Artificial Analysis is pitching AA-Briefcase as a long-horizon eval, not a prompt bundle. The launch thread says each scenario spans a multi-week project with linked tasks, shared organizational context, and deliverables like financial models, board decks, and design mockups.
The structure is heavier than most public agent benchmarks:
- Four private scenarios count toward the official leaderboard, per Artificial Analysis's launch thread.
- A fifth public scenario, AA-Briefcase Lite, was released through Hugging Face as a demo of structure, submission, and grading, according to Artificial Analysis's launch thread.
- Inputs include thousands of files, 25,000-plus Slack messages, and 3,500-plus emails, per Artificial Analysis's benchmark description.
- Scoring mixes binary rubric checks with pairwise grading on analytical quality and presentation quality, according to Artificial Analysis's benchmark description.
- Artificial Analysis says the tasks were built over months by experts with backgrounds including Google, McKinsey, and BCG, per Artificial Analysis's launch thread.
That design is the whole pitch. It tries to score whether an agent can survive messy institutional context, not just answer a clean question.
The first leaderboard
The top line is simple: Fable 5 leads, and there is still a large gap to the best open weights entrant.
- Claude Fable 5: 1587 Elo, per Artificial Analysis's results thread.
- Claude Opus 4.8: 1356 Elo, according to Artificial Analysis's results thread.
- GLM-5.2 max: 1266 Elo, the closest non-Anthropic model in the launch post and in Artificial Analysis's follow-up on GLM-5.2.
Community reaction quickly centered on GLM-5.2. Jeremy Howard's hands-on post called it at least as good as Opus 4.8 and GPT-5.5 in his own use, while bridgemindai's coding-index post also pointed to a seven-point jump on the Artificial Analysis Coding Index. AA-Briefcase did not put it at the top, but it did move it into the same conversation.
Where models still break
The ugly number in the launch is not the Elo spread. It is the ceiling.
Artificial Analysis's difficulty breakdown says Fable 5, the leader, fully satisfied every rubric criterion on only 3% of tasks. The same post says 31 of 91 tasks had no model above 50% on rubric criteria.
Artificial Analysis splits failure patterns by capability tier:
- Weaker models often miss relevant files, submit unusable deliverables, or fail to produce a deliverable at all, according to Artificial Analysis on failure modes.
- Stronger models more often complete the task shape but still miss embedded requirements scattered across source files, per Artificial Analysis on failure modes.
- Required file count matters. Artificial Analysis's file-count note said high-performance models fell from roughly 55% pass rates on prompt-only checks to about 40% when a check required five or more files.
That makes AA-Briefcase look less like an intelligence index clone and more like a retrieval, planning, and compliance stress test.
Cost per task
AA-Briefcase's first leaderboard has a brutal price spread.
- Claude Fable 5 averaged more than $31 per task, per Artificial Analysis's cost summary.
- Claude Opus 4.8 averaged $10.40, according to Artificial Analysis's launch thread.
- GPT-5.5 xhigh averaged $3.68, per Artificial Analysis's launch thread.
- GLM-5.2 max averaged $2.40, according to Artificial Analysis's launch thread.
- DeepSeek V4 Flash sat near $0.04 per task at the low end, per Artificial Analysis's cost summary.
Artificial Analysis framed the gap as roughly 800x from cheapest to most expensive. It also highlighted GLM-5.2 and DeepSeek V4 Pro as the strongest price-performance options, with Artificial Analysis's cost summary putting GLM-5.2 about 90 Elo behind Opus 4.8 for less than a quarter of the cost.
Turns, tokens, and image inspection
The benchmark also leaks a bit of workflow anatomy.
- Token usage ranged from 52 million for Grok 4.3 to 970 million for Claude Fable 5, according to Artificial Analysis on token usage.
- Excel deliverables drove around half of total token usage for nearly every model, per Artificial Analysis on token usage.
- Stronger models tended to take more turns, with Opus 4.8 at a 52-turn median and Fable 5 at 63, while Gemini 3.5 Flash reportedly took about 78 median turns without matching the leaders on Elo, according to Artificial Analysis on turn counts.
- Anthropic and MiniMax models used visual inspection heavily. Artificial Analysis's tool-use note said Fable 5 averaged about 21 view-image calls per task, while Opus 4.8 averaged about 12.
That last detail matters because AA-Briefcase includes artifact-heavy work. Artificial Analysis's tool-use note ties repeated image inspection to both overall Elo and Presentation Elo, which suggests rendered-output checking is part of the winning loop here.
Methodology questions
The benchmark landed with praise and caveats at the same time.
Ethan Mollick's reaction said AA-Briefcase looks like a good and impressive benchmark for real-world knowledge work, and specifically called out the private holdout tests and lack of saturation. In the same post, he noted he did not see a human comparison score.
That concern was already live before this launch. Mollick's earlier criticism argued Artificial Analysis's previous benchmark design leaned too much on AI judges and unclear human Elo estimation, while Mollick's follow-up said the broader index can still be directionally useful because many measures correlate even if validity remains weaker than real-world tasks.
Artificial Analysis has already been adjusting its cost methodology elsewhere. Artificial Analysis's Fable 5 pricing note said its v4.1 Intelligence Index now prices cached tokens at cache rates and credits fallback tasks to the model that actually served them. That note applies to a different eval, not AA-Briefcase directly, but it shows the company is still tuning how it turns agent runs into comparable numbers.