Claude Opus 4.7 releases with xhigh effort, /ultrareview, and 3x vision resolution
Claude Opus 4.7 is now generally available across Claude, the API, and major clouds with xhigh effort, higher-resolution vision, and Claude Code review upgrades. Prompt behavior, tokenization, and effort defaults changed enough that existing harnesses may need retuning.
TL;DR
- In claudeai's launch thread and the Anthropic announcement, Anthropic positioned Opus 4.7 as a same-price upgrade over 4.6, shipping across Claude, the API, Bedrock, Vertex, and Microsoft Foundry with a new
xhigheffort tier, higher-resolution vision, and Claude Code additions including/ultrareview. - The biggest first-party gains in claudeai's benchmark chart were on coding and vision-heavy work, while mikeyk added customer numbers from Cursor and Notion that framed the release as a real software-engineering upgrade rather than a version bump.
- The migration gotcha in natolambert's migration screenshot is the real story for production users: Opus 4.7 uses an updated tokenizer that can map the same input to 1.0 to 1.35x more tokens. That is a quiet token tax on anyone migrating. claudeai's API note says higher effort levels can also produce more output tokens.
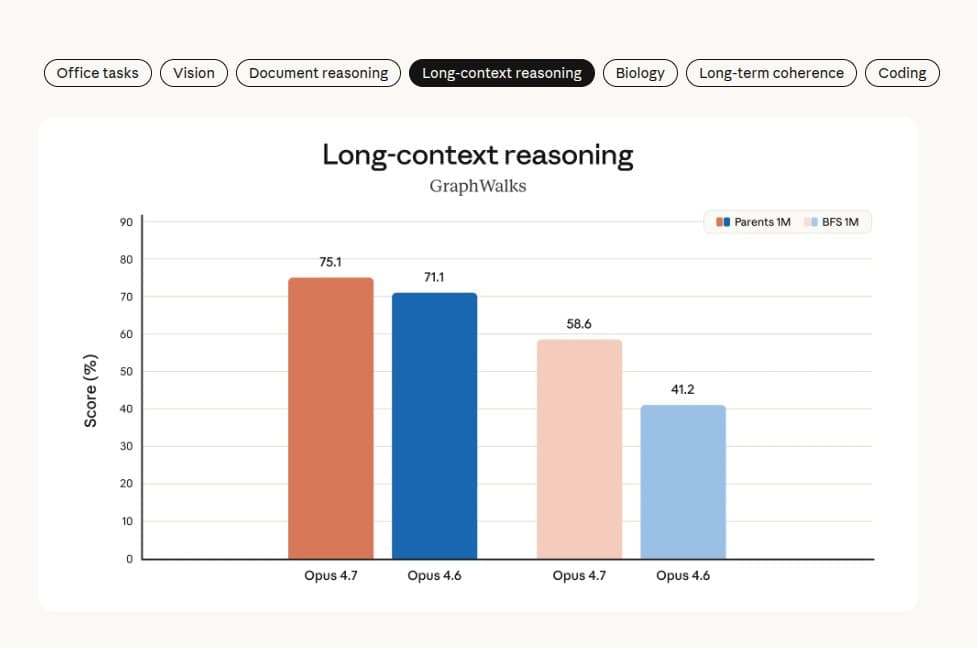
- The regression table inside scaling01's long-context screenshot and Yuchenj_UW's cyber excerpt showed that Anthropic improved a lot of headline numbers while landing weaker long-context retrieval and intentionally holding back cyber capability relative to Mythos Preview.
- The rollout was messy enough that ClaudeCodeLog's 2.1.112 note documented a same-day fix for Opus 4.7 auto mode, while Boris Cherny's reply and Boris Cherny's follow-up said Anthropic raised subscriber limits to offset the model's higher token use.
You can read the announcement, the system card PDF, the adaptive thinking docs, and the Claude Code best-practices page back to back and come away with a much more interesting picture than the launch post alone. The buried details are the tokenizer change, the forced shift to adaptive thinking on 4.7 surfaces, the new display field for summarized thinking, and Anthropic's decision to keep weak MRCR numbers in the card while arguing that GraphWalks is the benchmark it cares about now.
What shipped
- claudeai's availability post says Opus 4.7 is live on Claude, the Claude Platform API, and major cloud platforms.
- Anthropic's launch post lists unchanged pricing at $5 per million input tokens and $25 per million output tokens.
- claudeai's API note introduced
xhigh, a new effort level between high and max. - claudeai's API note also introduced task budgets in public beta.
- claudeai's Claude Code note added
/ultrareview, a dedicated review session for code changes. - claudeai's Claude Code note says auto mode was extended to Max users.
- claudeai's vision note says Opus 4.7 can see images at more than three times the prior resolution.
- Matt Pocock's screenshot says Claude Code now defaults to
xhigheffort for Opus 4.7. - The adaptive thinking docs say Opus 4.7 supports adaptive thinking only, while older fixed-budget extended thinking flows are deprecated or rejected on that model.
The model launch and the tooling launch were bundled tightly enough that the release reads like a platform migration, not just a new model slug.
Benchmarks that moved
First-party
- SWE-Bench Pro: 53.4% → 64.3%, +10.9 points, per claudeai's benchmark chart.
- SWE-Bench Verified: 80.8% → 87.6%, +6.8 points, per claudeai's benchmark chart.
- Terminal-Bench 2.0: 65.4% → 69.4%, +4.0 points, per claudeai's benchmark chart.
- OSWorld-Verified: 72.7% → 78.0%, +5.3 points, per claudeai's benchmark chart.
- Finance Agent v1.1: 60.1% → 64.4%, +4.3 points, per claudeai's benchmark chart.
- GPQA Diamond: 91.3% → 94.2%, +2.9 points, per claudeai's benchmark chart.
- CharXiv Reasoning, no tools: 69.1% → 82.1%, +13.0 points, per claudeai's benchmark chart.
- CharXiv Reasoning, with tools: 84.7% → 91.0%, +6.3 points, per claudeai's benchmark chart.
- MMMLU: 91.1% → 91.5%, +0.4 points, per claudeai's benchmark chart.
- OfficeQA Pro: 57.1% → 80.6%, +23.5 points, per scaling01's OfficeQA chart.
- GDPVal-AA Elo: 1619 → 1753, +134 Elo, per scaling01's GDPVal-AA chart.
- Structural Biology: 30.9% → 74.0%, +43.1 points, per scaling01's structural-biology chart.
Third-party evaluators
- Vals Index: 67.74% for Sonnet 4.6 → 71.47% for Opus 4.7, +3.73 points, per ValsAI's benchmark page link.
- Vibe Code Bench v1.1: 57.57% for Opus 4.6 no-thinking → 71.00% for Opus 4.7, +13.43 points, per the ValsAI leaderboard screenshot.
- ParseBench average score: 54.1 → 63.3, +9.2 points, while average price rose from 5.78¢ to 7.14¢ per page, +1.36 cents, per Jerry Liu's ParseBench table.
- Artificial Analysis hallucination rate: 61% → 36%, -25 points, per bridgemindai's Artificial Analysis chart.
Customer-reported
- CursorBench: 58% → 70%, +12 points, according to mikeyk's customer-results post.
- Notion evals: baseline unspecified → 14% lift, +14% relative, with one-third of the tool errors, according to mikeyk's customer-results post.
- Lovable task turns: baseline unspecified → 40% fewer turns, -40%, according to Lovable's launch post.
The pattern is easy to see. Anthropic spent this release on agentic coding, document reasoning, vision, and knowledge-work evals, then made sure customers had launch-day numbers to repeat.
Where it regressed
- MRCR v2 at 256K: Opus 4.6 scored 91.9% while Opus 4.7 scored 59.2%, -32.7 points, per eliebakouch's MRCR screenshot.
- MRCR v2 at 1M: Opus 4.6 scored 78.3% while Opus 4.7 scored 32.2%, -46.1 points, per scaling01's MRCR screenshot.
- BrowseComp: 83.7% → 79.3%, -4.4 points, per claudeai's benchmark chart.
- CyberGym: 73.8% → 73.1%, -0.7 points, per claudeai's benchmark chart.
- DeepSearchQA: Opus 4.6 scored 91.3% while Opus 4.7 scored 89.1%, -2.2 points, in eliebakouch's DeepSearchQA screenshot.
Boris Cherny, Claude Code lead at Anthropic, responded directly in Boris Cherny's MRCR reply. He said Anthropic kept MRCR in the system card for scientific honesty but is phasing it out because it overweights distractor-stacking and underweights applied long-context work, pointing instead to GraphWalks in the system card PDF.
Anthropic also disclosed a deliberate cyber tradeoff. The excerpt in Yuchenj_UW's system-card screenshot says Opus 4.7 is the first model used to test new cyber safeguards and that Anthropic experimented during training with reducing those capabilities relative to Mythos Preview.
Under the hood
The migration guide and docs changed more than the model card headline suggested.
- Tokenizer swap: the migration guide says the same input can map to 1.0 to 1.35x more tokens on Opus 4.7.
- Adaptive thinking: the adaptive thinking docs say Opus 4.7 uses adaptive thinking only.
thinking.type: "enabled"is rejected on 4.7. - Reasoning control: claudeai's API note and the best-practices page place
xhighbetween high and max, with Anthropic recommending high or xhigh for coding and agentic work. - Vision ceiling: claudeai's vision note says Opus 4.7 can process images at more than three times the previous resolution, and alexalbert__ tied that to better interfaces, slides, and docs.
- Prompt behavior: nrehiew_'s migration screenshot says 4.7 follows instructions more literally and speaks in a more direct tone. Anthropic explicitly recommends prompt and harness review during migration.
- Thinking display: badlogicgames' docs link points to the adaptive-thinking docs that add a
displayfield for summarized thinking. That detail also came up in the main Hacker News thread.
List price stayed flat, but the effective cost story did not. AiBattle_'s pricing screenshot shows list pricing unchanged from 4.6, while madiator's migration screenshot and Boris Cherny's rate-limit post confirm that Anthropic simultaneously shipped higher token use and raised limits to compensate.
Vibe Check
Hands-on reports converged faster than usual, and they were unusually workflow-specific.
- Boris Cherny, Claude Code lead at Anthropic, used his workflow thread and his follow-up to push a delegation-first style: auto mode on, longer tasks, explicit verification, and
xhighfor most work. - _catwu's guidance thread made the same point in plainer language: give the full task context up front, let auto mode handle permissions, and tell Claude how to verify changes.
- Theo's first bench said Opus 4.7 wrote better modernization plans than expected on a long upgrade task, though Theo's follow-up still caught a missed Next.js
Linkmigration detail. - Yuchenj_UW's hands-on report said max-effort 4.7 handled large codebases and architecture diagrams noticeably better than 4.6, with one instruction-misread caveat.
- Jeremy Howard's hands-on thread described a less overbearing interaction style, saying 4.7 was more willing to discuss and less likely to barge ahead.
- Ethan Mollick's adaptive-thinking complaint and Ray Fernando's web-app complaint show the opposite side of the same change: on non-code surfaces, people quickly ran into the limits of an effort router they could not always override.
The split is clean. Claude Code users mostly talked about longer agentic runs. Web and mobile users mostly talked about adaptive thinking deciding not to think when they wanted it to.
Where it shows up
The day-one integration list was huge, which is part of why this launch felt bigger than a routine Opus bump.
- Cursor launched Opus 4.7 with a temporary 50% discount.
- Warp added Opus 4.7 across paid plans and advertised 50% off usage through April 30.
- Lovable added support and claimed 40% fewer turns on its own benchmarks.
- Cognition made Opus 4.7 available as an agent preview inside Devin.
- Cline added the model under the slug
anthropic/claude-opus-4.7. - Replicate listed Opus 4.7 with 1M context.
- OpenRouter shipped the model and linked its own migration guide.
- Wes Roth's Copilot screenshot showed Opus 4.7 turning up inside Microsoft 365 Copilot surfaces on day one.
- Azure's Foundry post and claudeai's availability note place it in Microsoft Foundry alongside Bedrock and Vertex.
- Tembo, Conductor, Hermes Agent, Hyperbrowser, and Hyperbrowser's follow-up all pushed it into agent products almost immediately.
The Claude Code rollout kept moving after launch. ClaudeCodeLog's 2.1.111 changelog bundled xhigh, /ultrareview, and permission changes with the model launch, then ClaudeCodeLog's 2.1.112 fix shipped four hours later to fix auto mode incorrectly reporting that claude-opus-4-7 was unavailable.