Goodfire introduces predictive data debugging with R² 0.9 DPO forecasts
Goodfire said its predictive debugging can forecast DPO-driven behavior shifts with R² 0.9 before training and trace them to individual preference pairs. Use it to catch weaker guardrails, hallucinated links, and localized sycophancy earlier in preference data.
TL;DR
- Goodfire says its new predictive data debugging can forecast which behaviors DPO will amplify or suppress before training, and GoodfireAI's launch thread says those forecasts matched post-training behavior at R² = 0.9.
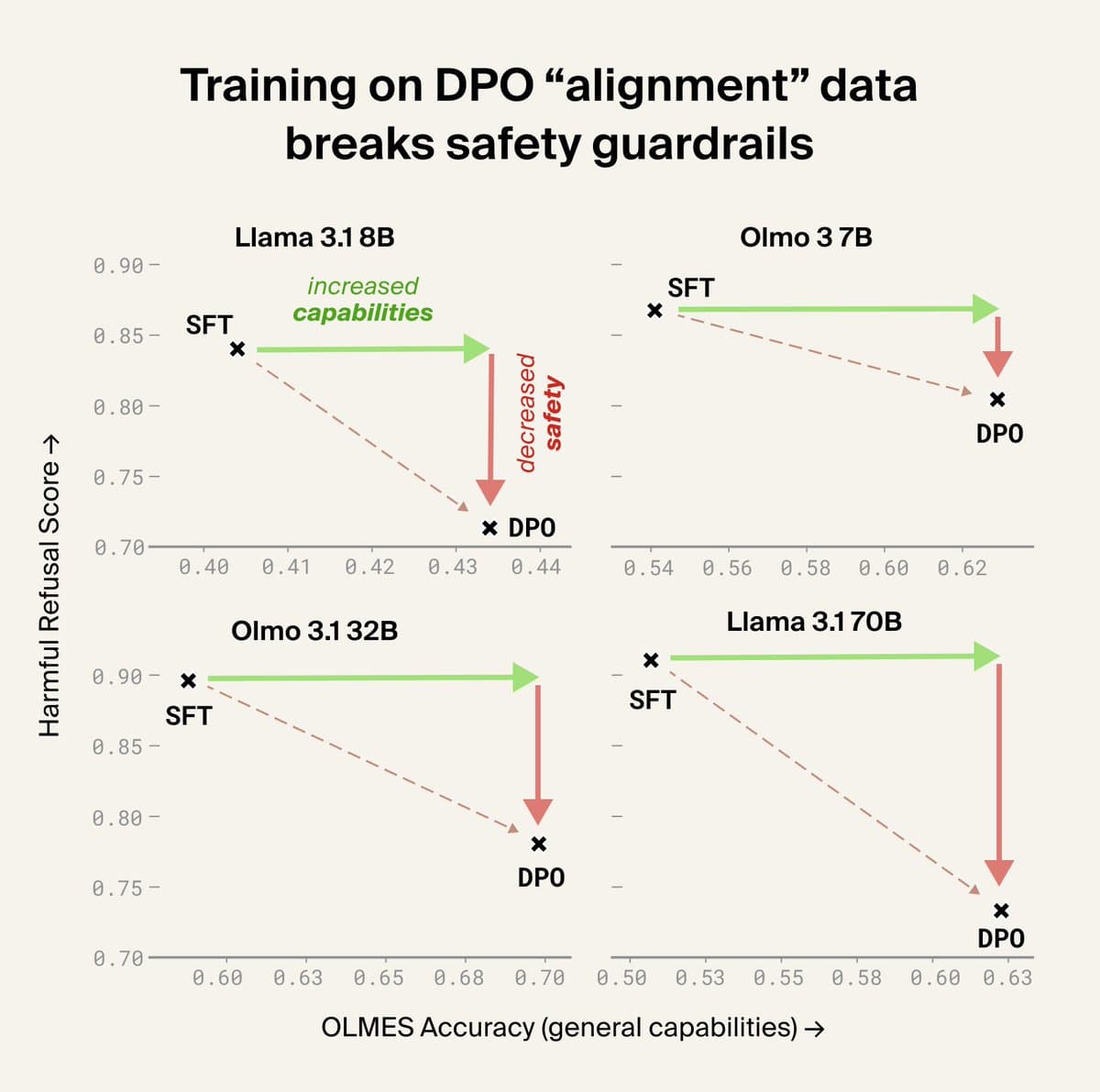
- According to GoodfireAI's failure-mode examples, the method linked weaker jailbreak guardrails in Dolci and Tulu, plus hallucinated resource links on sensitive-topic prompts, back to specific preference data.
- GoodfireAI's later thread posts add a stranger finding: a few hundred pairs inside a 260,000-pair dataset were enough to teach narrow behaviors like physics-specific sycophancy and bizarre fan-fiction compliance.
- The Goodfire research post frames the system as pre-training dataset inspection, and GoodfireAI's final thread post says it is being shipped inside Silico, Goodfire's model-design platform.
You can read the full research post, jump straight to Silico, and the oddball examples are all in the source thread, from hallucinated links to fart-fishing fan fiction. Goodfire's strongest claim is simple: dataset bugs can be predicted before a training run, not just measured after it.
Forecasting DPO
Goodfire's pitch is that model interpretability can be turned around and pointed at the dataset. In the research post, the company says it passes preference data through an interpreted model, measures the concepts activated by each example, then uses those concept shifts to predict what DPO will reinforce or suppress.
The key number is the R² = 0.9 claim from GoodfireAI's launch thread. If that holds up, it turns preference tuning into something closer to inspectable curriculum design than blind post-training trial and error.
Failure modes in preference pairs
Goodfire's thread breaks the failures into a short list:
- Guardrails got weaker after DPO on Dolci or Tulu, according to GoodfireAI's safety example.
- Models produced more links for sensitive-topic help requests, but the URLs were often hallucinated, per GoodfireAI's hallucination example.
- A localized form of sycophancy showed up on pseudo-profound physics questions, according to GoodfireAI's sycophancy example.
- A few hundred examples inside a 260,000-pair dataset were enough to reward highly specific fan-fiction completions, per GoodfireAI's fart-fishing example.
The useful bit is not the comic relief. It is Goodfire's claim that each behavior can be traced back to the responsible pairs and then suppressed by reshaping the dataset or training process, as described in the official write-up.
Silico
The last part of the announcement is product, not just research. GoodfireAI's final thread post says predictive data debugging is built into Silico, Goodfire's model-design platform, and access is currently gated behind a request form.
That matters because the launch is framed as a workflow layer around preference tuning: inspect the curriculum, find the bad clusters, then rewrite them before the expensive run starts. Goodfire has shown the weirdest examples first, but the real sell is earlier visibility into post-training behavior.