Mistral releases Voxtral TTS with 3-second cloning and 68.4% win rate vs ElevenLabs Flash v2.5
Voxtral TTS uses separate semantic and acoustic token models, a 2.14 kbps codec, and 3-25 second reference audio for cloning across nine languages. Try it if you want a hybrid speech pipeline with more control and faster acoustic synthesis than all-autoregressive generation.
TL;DR
- Mistral’s Voxtral TTS announcement and model docs say the new 4B open-weights model does zero-shot voice cloning from about 2 to 3 seconds of reference audio, supports nine languages, and targets low-latency voice agents launch thread.
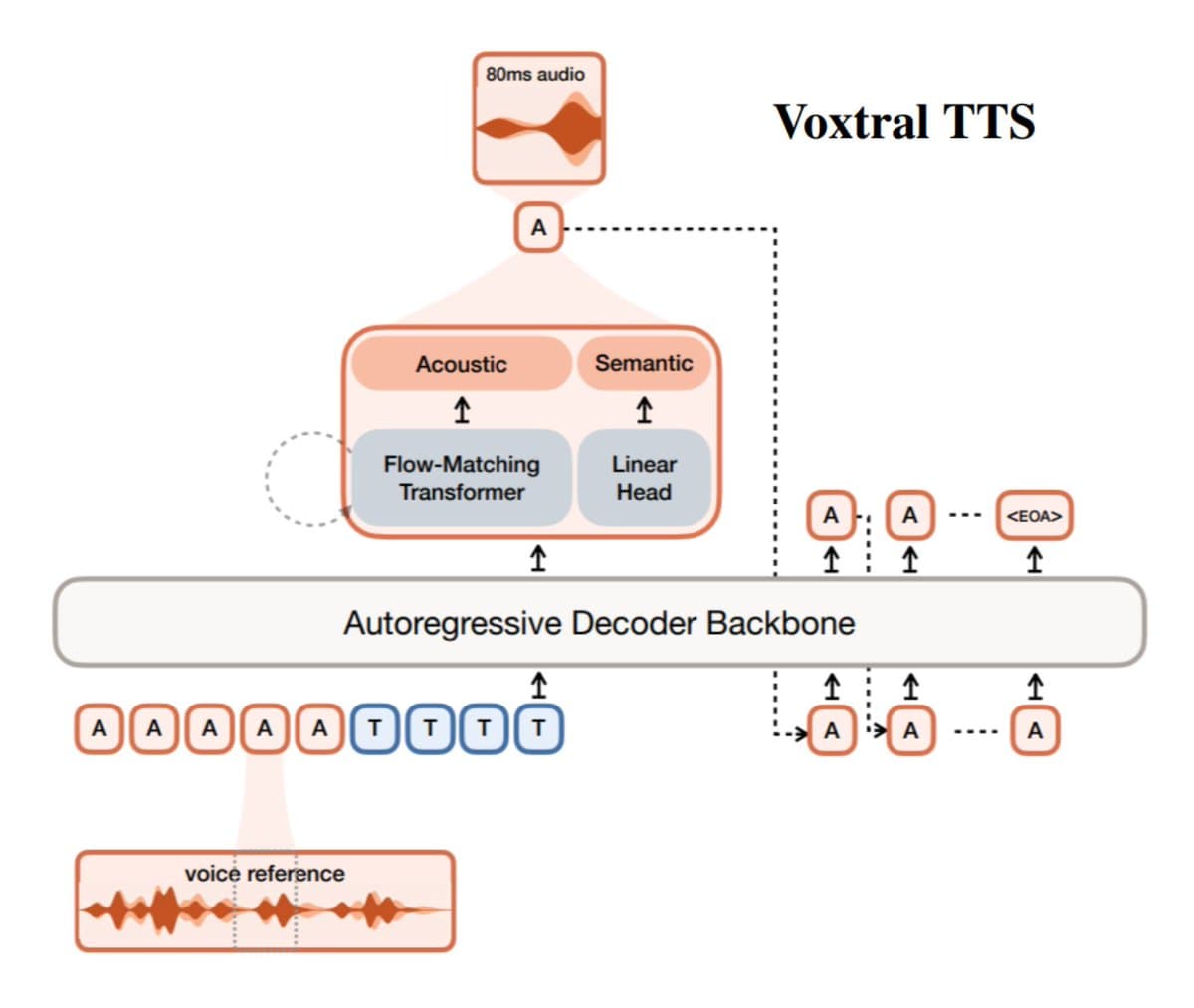
- The core architectural bet is to split speech generation into semantic tokens for content and acoustic tokens for voice, instead of making one autoregressive model do both jobs architecture thread.
- The codec is unusually compact, 1 semantic token plus 36 acoustic tokens at 12.5 Hz, or about 2.14 kbps total, which helps explain why the system can stream quickly codec details.
- Mistral says native speakers preferred Voxtral for multilingual voice cloning over ElevenLabs Flash v2.5 in 68.4% of pairwise judgments, a claim repeated in the paper and launch materials benchmark claim.
- The open release is practical, not just academic: the API docs expose streaming TTS, while the Hugging Face model card shows vLLM-Omni deployment on a single 16 GB+ GPU weights and links.
You can read the official launch post, jump straight to the model page, and skim the API docs for the oddest detail: Mistral treats the reference voice as an instruction signal, so rhythm and emotion come from the prompt clip without extra prosody tags. The paper makes the same point more mechanically, with a split pipeline, a tiny codec, and flow matching for the acoustic side.
Semantic tokens and acoustic tokens
Mistral’s main design choice is to separate what is being said from how it sounds. That is the whole story here, and it is a smart break from all-in-one autoregressive speech stacks.
According to the paper and launch materials, Voxtral uses a decoder-only autoregressive transformer for semantic tokens, then a flow-matching model for acoustic tokens. The split gives the first stage the long-range coherence needed for linguistic structure, while the second stage handles prosody and timbre with a generator better suited to continuous audio.
Voxtral Codec
The codec numbers are compact enough to matter on their own.
The thread and paper describe Voxtral Codec as:
- 1 semantic token
- 36 acoustic tokens
- 12.5 Hz frame rate
- about 2.14 kbps total
That tokenization scheme sits underneath the rest of the model. It is also the cleanest explanation for why Mistral can pair voice cloning with streaming, instead of treating high-quality synthesis and low latency as opposing goals.
Hybrid training and acoustic generation
The training recipe mirrors the architecture split.
The semantic side is trained with ASR distillation so the token stream tracks real linguistic structure. The acoustic side is modeled continuously with flow matching, and the thread says it can produce high-quality audio in about eight steps.
Mistral also extends DPO across both halves of the system:
- a discrete objective for semantic tokens
- a continuous objective for acoustic tokens
That is a more interesting detail than the headline benchmark. It suggests Mistral is treating preference optimization as a multimodal control layer, not just a text-model fine-tuning trick.
API latency, formats, and deployment
The docs are more concrete than the tweet thread about how Voxtral actually ships.
The API docs say Voxtral supports English, French, Spanish, Portuguese, Italian, Dutch, German, Hindi, and Arabic, plus cross-lingual voice cloning and code-mixing. They also give real latency numbers: about 90 ms model processing time, around 0.8 seconds end-to-end time-to-first-audio for PCM, and about 3 seconds for MP3.
The Hugging Face model card adds the deployment picture: 24 kHz output in WAV, PCM, FLAC, MP3, AAC, and Opus, 20 preset voices, BF16 weights, and vLLM-Omni support on a single GPU with at least 16 GB of memory. The release is under CC BY-NC 4.0, inherited from the reference-voice data used to ship the model and sample voices.