Qwen3.7 Max ships implicit caching for no-setup context reuse
Alibaba rolled out implicit caching for Qwen3.7 Max, automatically reusing repeated context without user setup. The update also lands with fresh benchmark results and broader coding-agent support across OpenCode and Hermes Agent.
TL;DR
- Alibaba says Alibaba_Qwen's caching post has turned on implicit caching for Qwen3.7-Max, so repeated context can be reused automatically without any setup.
- Fresh evals were mixed but strong: arena's Code Arena post placed Qwen3.7 Max at No. 4 on Code Arena: Frontend, while ValsAI's benchmark thread scored it at 57.3% on the Vals Index and petergostev's BullshitBench update said the non-thinking variant outperformed the thinking mode on that benchmark.
- The rollout is already showing up in agent tooling, with opencode's model support post adding Qwen3.7 Max to OpenCode and NousResearch's Hermes Agent post adding Hermes Agent support.
- The practical tradeoff in early third-party testing was speed versus depth: ValsAI's setup note used a roughly 1M context window and 65k max output tokens, while ValsAI's latency breakdown reported very slow agentic runs and a higher per-test cost than Qwen 3.6 Plus.
Alibaba paired the caching rollout in its official post with a link to explicit cache best practices, and the surrounding evidence filled in the rest of the picture. You can check the live Code Arena board, browse ValsAI's full results, and see that support landed quickly in both OpenCode and Hermes Agent.
Implicit caching
Alibaba's pitch was simple: implicit caching now runs in the background on Qwen3.7-Max, automatically detecting reusable context and making repeated calls faster and cheaper.
The interesting wrinkle is that Alibaba did not position this as a replacement for manual controls. In the same post, Alibaba_Qwen said users who want higher or more deterministic hit rates should still use explicit caching instead, and linked to the explicit cache guide.
Benchmark placements
Two benchmark reads stood out right away:
- Code Arena: Frontend put Qwen3.7 Max at No. 4, according to arena's announcement, with arena's correction clarifying that the title should read rank No. 4 to match the visual leaderboard.
- Vals Index gave it a 57.3% score and ranked it fifth, according to ValsAI's post.
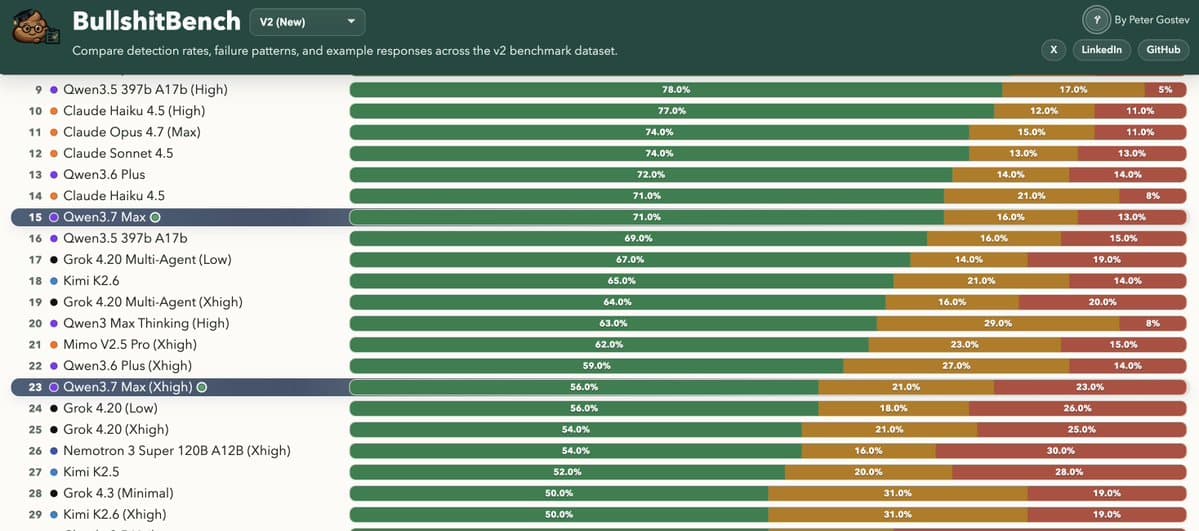
- BullshitBench looked weirder. petergostev's update said the non-thinking version landed 15th, while the xHigh thinking mode fell to 23rd, which he described as worse than the non-thinking setup.
That makes the early picture less like one clean victory lap and more like a model that looks especially credible on coding and agentic web work, while still showing mode-dependent behavior on other evals.
Agent surfaces
Tooling support appeared almost immediately.
- OpenCode added Qwen3.7 Max with text-only support, a 1M context window, and language calling it the smartest model in the Qwen family so far, per opencode's support post.
- Hermes Agent added support the same day, per NousResearch's announcement.
- Community posts like itsPaulAi's hands-on thread framed that combination as enough to swap Qwen3.7 Max into existing coding-agent workflows in place of more expensive frontier models.
- kilocode's usage snapshot also said Qwen 3.7 Max showed up on Kilo Gateway earlier than expected.
Vals setup and latency
Vals' thread added the clearest concrete operating numbers in the evidence set.
- Endpoint: Alibaba Cloud, according to ValsAI's setup note
- Generation settings: temperature 0.7 with preserve_thinking enabled, per ValsAI's setup note
- Limits: about 1M context and 65k max output tokens, per ValsAI's setup note
- Average latency on the Vals Index: 1,778 seconds, according to ValsAI's latency breakdown
- Slowest agentic slices: VCB at 6,683 seconds and IOI at 4,380 seconds, per the same breakdown
- Faster non-agentic slices: GPQA at 127 seconds, MMLU-Pro at 29 seconds, CorpFin at 20 seconds, again per ValsAI's numbers
- Cost per test: $5.30 versus $1.43 for Qwen 3.6 Plus, according to ValsAI's comparison
Those numbers are the most concrete reminder that the Qwen3.7-Max story was not only about a no-setup cache toggle. The same launch window also surfaced a model with long-context, long-runtime agentic ambitions, plus the latency bill that comes with them.