Z.ai releases GLM-5.1, a 744B open model with 58.4 SWE-Bench Pro and 8-hour agent runs
Z.ai released GLM-5.1, a 744B open model built for long-horizon agentic coding and ranked first among open systems on SWE-Bench Pro. Day-0 support in OpenRouter, Ollama, SGLang, vLLM, OpenCode, and local quantization paths makes it ready to test in existing stacks.
TL;DR
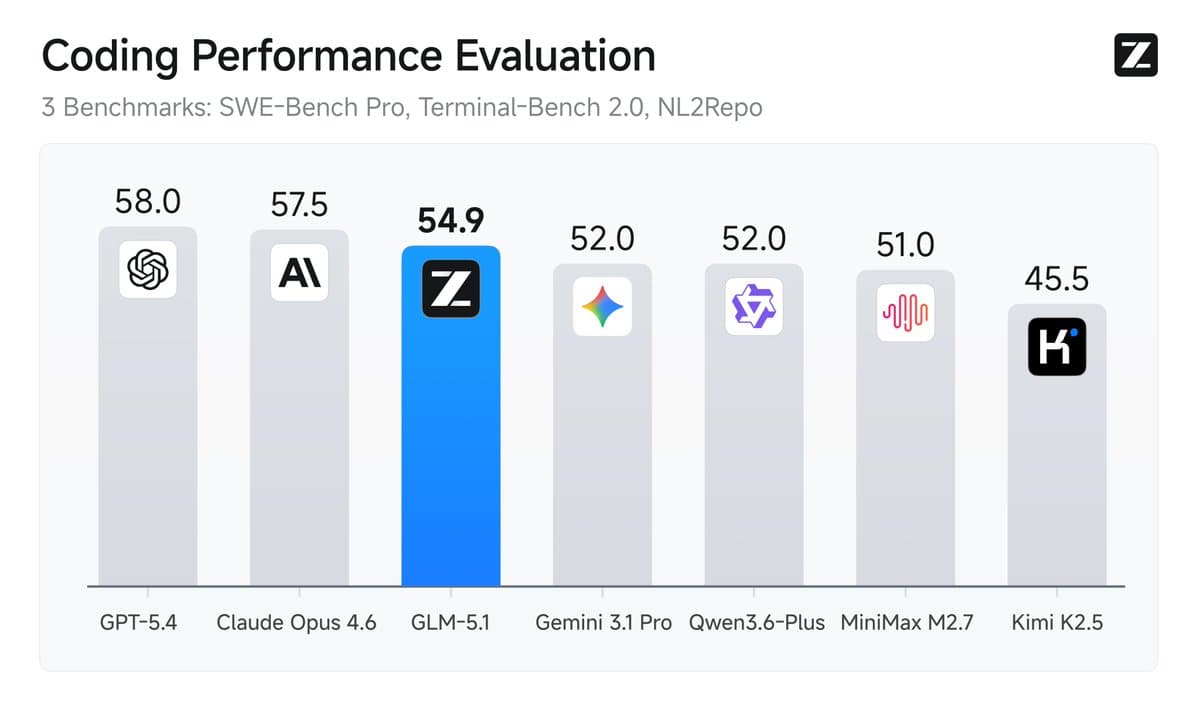
- Z.ai's launch thread says GLM-5.1 is a 744B open model aimed at agentic coding, and Official launch post claims 58.4 on SWE-Bench Pro, ahead of GPT-5.4 at 57.7 and Claude Opus 4.6 at 57.3.
- The bigger claim in Official launch post is duration, not just first-pass score: GLM-5.1 is presented as sustaining 600-plus optimization iterations and 6,000-plus tool calls, while Z.ai frames it as an 8-hour autonomous agent run.
- Distribution was unusually fast. OpenRouter, SGLang, vLLM, Ollama, and OpenCode all announced GLM-5.1 support on launch day.
- Local deployment showed up immediately too. Unsloth published a Dynamic 2-bit GGUF that shrinks the model from 1.65 TB to about 220 GB, and the Hugging Face model card lists the weights under an MIT license.
- Early external scoreboards were flattering but more uneven than the headline number. ValsAI put GLM-5.1 at No. 1 among open-weight models on its index, while ValsAI's follow-up also logged weaker rankings on TaxEval and CaseLaw.
You can read the official post, skim the API docs, and grab the weights on Hugging Face. The launch also came with ready-made serving paths in vLLM recipes and an SGLang cookbook, plus immediate hosted access through OpenRouter and Ollama Cloud.
SWE-Bench was the headline, long-horizon runs were the pitch
The benchmark headline is simple: Official launch post reports 58.4 on SWE-Bench Pro, 42.7 on NL2Repo, and a lead over GLM-5 on Terminal-Bench 2.0. Z.ai's summary chart collapses those into a single coding composite where GLM-5.1 trails GPT-5.4 and Opus 4.6 overall, but the company chose SWE-Bench Pro as the flagship number for a reason.
The more interesting material in the post is the long-horizon evidence. Z.ai says GLM-5.1 pushed a vector database optimization task through 655 iterations and more than 6,000 tool calls, reaching 21.5k QPS after starting from a single-run frontier of 3,547 QPS. The same post also claims a 3.6x geometric mean speedup on KernelBench Level 3 over 1,000-plus turns, and an 8-hour web build loop that kept expanding a Linux-style desktop instead of stopping at a static mockup.
That makes GLM-5.1 feel less like a pure model-card refresh and more like a bet that agent benchmarks should reward staying useful after turn 100.
The API surface is built for coding agents
The GLM-5.1 docs describe a 200K context window with 128K output, streaming responses, structured JSON output, MCP integration, caching for long conversations, and explicit thinking controls. The sample API call uses an OpenAI-style chat completions endpoint with thinking.type set to enabled, which is exactly the kind of surface area coding-agent frameworks already expect.
OpenRouter's model page exposed the same launch-day shape in hosted form: 202,752 context, 131K max output on at least one route, and pricing starting around $1.26 per million input tokens and $3.96 per million output tokens. Z.ai's own blog also says GLM-5.1 is compatible with Claude Code and OpenClaw, which explains why so many tool vendors could wire it up immediately.
A Hacker News thread added one early reality check: some testers said the one-shot behavior looked stronger than the long-horizon story in their own experiments.
Serving support landed everywhere on day 0
The deployment story was unusually complete for a same-day open release.
- SGLang posted launch commands for both FP8 and BF16, using dedicated
glm45reasoning andglm47tool-call parsers. - vLLM published a Docker recipe with
--enable-auto-tool-choice, FP8 weights, and tensor parallel size 8, then linked to a full GLM recipe page. - Ollama added
glm-5.1:cloudimmediately, plus direct launch hooks for OpenClaw and Claude Code. - OpenCode announced availability with zero data retention.
- OpenRouter's model page went live the same afternoon.
That stack coverage matters because it turns a benchmark launch into something engineers can actually slot into existing agent runtimes without waiting for adapter work.
A local run path appeared within hours
The raw model is still giant. Official launch post says the public release includes full weights for local deployment, and the Hugging Face model card tags the repo as MIT-licensed and endpoint-compatible.
What changed the local story was quantization speed. Unsloth says its Dynamic 2-bit GGUF cuts GLM-5.1 from 1.65 TB to roughly 220 GB, enough to fit on a 256 GB unified-memory Mac or equivalent RAM and VRAM setups. The same release notes mention a 202,752-token context window, llama.cpp instructions, and even a chat template update for tool use.
That does not make GLM-5.1 a casual laptop model. It does make it a same-weekend experiment instead of a cluster-only curiosity.
Early external rankings were broad, but not clean sweeps
The first outside scoreboards mostly backed the launch narrative. ValsAI said GLM-5.1 became the No. 1 open-weight model on its index, unseating Kimi K2.5, and Arena said it launched straight to the top open-model slot in Text Arena, 11 points ahead of GLM-5.
The Vals thread also added useful texture. ValsAI's breakdown says GLM-5.1 led open-weight models on MedCode, Vibe Code Bench, Terminal Bench 2, SWE Bench Verified, and a finance-agent benchmark, but fell to No. 8 on TaxEval and No. 13 on CaseLaw. The same post priced it at about $0.22 per test on the index, above Kimi's $0.12 but well below Sonnet 4.6 and GPT-5.4.
Those are still early leaderboard snapshots, but they make the launch look broader than a single SWE-Bench spike and narrower than a universal win.