Cursor
The AI Code Editor
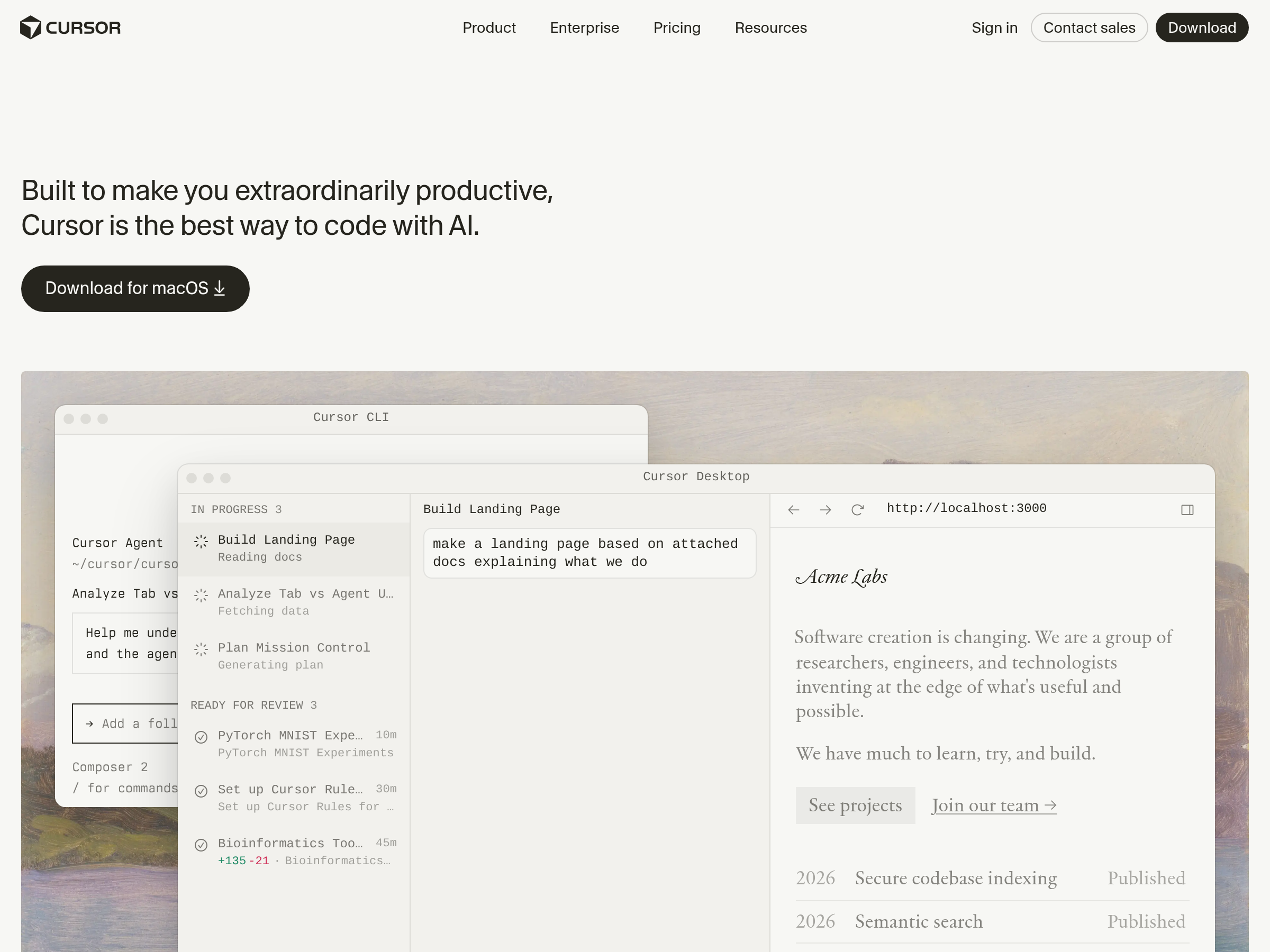
An AI-powered code editor for software development.
Recent stories
Cursor published research showing coding models can retrieve known fixes from git history or public mirrors instead of independently solving tasks. Under a stricter harness, Opus 4.8 fell from 87.1% to 73.0% and Composer 2.5 from 70.5% to 60.5%.
Cursor now lets developers move local agents to the cloud so work can continue after the laptop closes, with mobile as the handoff control surface. The change removes one of the main setup frictions in long-running cloud sessions.
Databricks open-sourced Omnigent, a meta-harness that runs Claude Code, Codex, Cursor, Pi, and custom agents in one live session with a collaborative web UI. The release centralizes supervision, cost control, and cross-agent review instead of splitting work across separate tools.
Cursor launched Origin, a code storage and Git hosting product built for agent-heavy workflows, with API and MCP extensibility plus conflict-handling for parallel changes. It matters because multi-agent coding shifts the bottleneck from generation to branch, diff, and merge orchestration.
Cursor said it agreed to a $60B all-stock deal with SpaceX, with closing targeted for Q3 and Cursor remaining a wholly owned subsidiary. The deal ties a major coding-agent channel to SpaceX compute and gives Cursor a new strategic owner.
Codex usage moved further into phone-first workflows, with iOS dictation loops, background voice capture, and app updates like searchable settings and restored state. The comparisons still flag rough spots in multi-thread UX, Windows support, and cases where CLI tabs or cloud agents are easier to manage.
Cursor shipped Design Mode, letting users point at elements, draw annotations, or speak changes directly against a UI. The feature pushes more frontend iteration into the editor and narrows the gap between interface feedback and code changes.
Uber set a $1,500 monthly limit for each AI coding tool an employee uses, covering products such as Cursor and Claude Code. The cap gives enterprises an early benchmark for coding-agent spend as token costs outgrow typical software-seat budgets.
Cursor raised usage limits for all Teams users and introduced a Premium seat tier with 5x usage for 3x the price. Teams can now budget coding-agent access around seat quotas instead of raw token meters.
Independent developers shipped sidecars that let Claude Code, Cursor, and Codex share memory, hot-swap model providers, package local projects as apps, and automate browser QA. Try these reusable tools if you want memory, routing, QA automation, and app packaging outside editor-specific features.
Cursor shipped auto-review mode, letting agents run more tool calls with fewer approval prompts and sending unsafe or unsandboxed actions to a classifier subagent. The change lowers review friction while keeping a separate path for higher-risk calls.
Independent IDEs, gateways, and agent runtimes rolled out Claude Opus 4.8 within hours of launch, including Cursor, Warp, OpenRouter, and Perplexity. That matters because teams can benchmark or swap the model into existing workflows without waiting for connector lag.
Cursor's Developer Habits Report says input tokens account for about 70% of price-equivalent coding-agent costs as agents read more context. The report also says auto-accepted code is up 5x since the start of the year, so teams should watch context usage and review rates.
New guides, plugins, and reusable libraries show the Agent Skills format moving beyond Claude Code into multiple coding-agent clients and runtimes. That matters because workflows are becoming portable artifacts instead of one-off prompts tied to a single harness.
Cursor opened a Python and TypeScript SDK for building custom agents on Composer 2.5 and paired the launch with a 90% usage discount for the long weekend. Artificial Analysis data still shows Composer 2.5 leading on cost per task, making the SDK launch an efficiency play for builders.
Turbopuffer said it crossed a $100M run-rate while staying profitable on less than $1M raised, and said Cursor moved production search onto the stack with a 95% cost reduction. The milestone matters because AI products increasingly compete on retrieval quality and cost, not just model output.
Artificial Analysis put Composer 2.5 at 62 on its Coding Agent Index, third overall, with standard mode at about $0.07 per task and Fast at $0.44. The update matters because Cursor is now benchmarking as a low-cost agent option, not just a bundled fallback model.
Cursor released Composer 2.5 in its editor and says it is stronger on long-running tasks, with included usage doubled for a week. Early comparisons place it near Opus 4.7-class coding, and Cursor says a much larger model is still training with 10x more compute.
Leak videos and tester reports pointed to a larger Gemini desktop app with Stream to Cursor, Spark local-file access, Live, and Omni ahead of I/O. Independent testers also reported faster 3.2 and 3.5 Flash checkpoints, but Google had not announced the features publicly.
Kimi released Web Bridge, a browser extension that lets agents search, scroll, click, type, and save repeatable skills across websites. The bridge works with Kimi Code CLI plus Claude Code, Cursor, Codex, Hermes, and other agents.
Cursor added reusable cloud development environments for agents with multi-repo setup, rollback, and scoped secrets. The update moves cloud agents closer to laptop-style setups while keeping long-running work isolated and auditable.
Anthropic rolled fast mode for Opus 4.7 into Claude Code and tools including Cursor, v0, Droid, Conductor, and OpenRouter. Use it where latency matters, but watch pricing: Cursor disclosed a 6x multiplier and others treat it as premium.
Artificial Analysis launched a Coding Agent Index for model-and-harness pairs, while OpenHands refreshed its model leaderboard. The results show harness choice matters, with cost varying over 30x and task time over 7x across stacks.
User posts and HN threads compared GPT-5.5 and Opus 4.7 across plan mode, frontend work, and 120K-context sessions. The split results mean token burn and instruction discipline matter as much as raw benchmark scores.
Cursor added always-on agents that monitor GitHub, investigate failing runs, and open fix PRs automatically. That moves coding agents beyond the editor and into CI recovery after commits land.
Raindrop launched Triage, a Slack-based agent that finds traces, summarizes recurring failures, runs recurring briefs, and opens experiments from production conversations. Teams using Claude Code, Cursor, or Devin can plug it into agent ops to shorten debugging loops.
Cursor's Team Kit packages internal skills like /verify-this, CLI and UI automation harnesses, PR cleanup, and /loop-on-ci, installable with /add-plugin cursor-team-kit. It turns several internal review and validation habits into reusable commands for agent-driven coding workflows.
Developers posted 11 early Cursor SDK integrations, including QA agents, Gmail-to-Chat handoffs, Chrome extensions, CI autofix, doc sync, and multi-repo orchestration. The demos show Cursor agents moving outside the IDE into existing team workflows with reusable cloud-agent patterns.
Cursor shipped a TypeScript SDK that exposes its runtime, harness, and models for CI/CD jobs, background automations, and embedded agents. The launch lets teams treat Cursor as programmable agent infrastructure, though it still depends on Cursor API access.
Users and third-party evals reported shorter runs, stronger long-context scores, and faster rollout into Cursor and other tools a day after GPT-5.5 hit the API. Higher per-token pricing may be partly offset by lower loop time and fewer tool-call stalls, so watch early bench data before changing defaults.
Independent tools and platforms shipped GPT-5.5 support within a day of the API rollout, spanning IDEs, hosted research agents, enterprise stacks, and coding agents. That shortens evaluation time because teams can test the model inside existing workflows instead of rebuilding around a single OpenAI surface.
Cursor 3.2 added /multitask async subagents, improved worktrees, and multi-root workspaces, then paired the release with GPT-5.5 rollout at 72.8% on CursorBench. The update makes background agent orchestration a first-class IDE workflow instead of a blocking queue.
Cursor 3 adds split-agent panes, tighter cloud-agent controls, voice input fixes, and an 87% reduction in dropped frames during large edits. The update makes the IDE easier to use as a mixed local-cloud agent workspace, while keeping editor navigation and diff review intact.
Cursor 3 introduced a separate agent-first workspace that can run agents locally, in worktrees, over SSH, and in the cloud while keeping the editor available. The release gives teams a path to multi-agent orchestration without giving up the traditional IDE surface.
OpenClaw 2026.3.28 exposes messaging and event handling as nine MCP tools, adds Responses API support, and lets plugins request permission during browser use. Use it to separate transport from agent logic so Claude Code, Codex, Cursor, and local harnesses can share the same account with less glue.
Expect wraps browser QA for Claude Code, Codex, or Cursor into a CLI that records bug videos and feeds failures back into a fix loop. It gives coding agents a tighter UI validation cycle without requiring a custom browser harness.
Cursor shipped Instant Grep, a local regex index built from n-grams, inverted indexes, and Bloom filters that drops large-repo searches from seconds to milliseconds. Faster candidate retrieval shortens the coding-agent loop, especially when ripgrep-style scans become the bottleneck.
Vercel's Next.js evals place Composer 2 second, ahead of Opus and Gemini despite the recent Kimi-base controversy. The result matters because it separates base-model branding from measured task performance on a real framework workflow.
Cursor and Kimi said Composer 2 starts from Kimi K2.5, with continued pretraining and RL added on top after developers spotted Kimi model IDs in traffic. Teams should benchmark it as a productized open-base stack, not a from-scratch model.
Cursor shipped Composer 2 with gains on CursorBench, Terminal-Bench 2.0, and SWE-bench Multilingual, plus a fast tier and an early Glass interface alpha. It resets the price-performance baseline for coding agents and shows Cursor is now a model company as much as an IDE.
NVIDIA introduced a coalition of labs and platform vendors to co-develop open frontier models, including Mistral, LangChain, Perplexity, Cursor, Reflection, Sarvam, and Black Forest Labs. Watch it if you want open-model efforts tied to DGX Cloud, NIM, and production tooling instead of weights alone.
Cursor published its internal benchmarking approach and reported wider separation between coding models than SWE-bench-style leaderboards show. Use it as a reference for production routing decisions, but validate results against your own online traffic and task mix.