OpenAI reports beneficial RL improves 44 of 53 evals and transfers beyond health
OpenAI said reinforcement learning on realistic conversations improved 44 of 53 alignment and benefit evaluations, including transfer from health-only training to deception and reward-hacking tests. The result suggests a broader behavioral shift rather than narrow task tuning, but the claim is based on OpenAI’s own eval mix rather than a single public benchmark.
TL;DR
- OpenAI said a model trained with reinforcement learning on realistic conversations improved on 44 of 53 alignment and benefits evaluations, according to OpenAI's eval summary and Karan Singhal's thread recap.
- The oddest result is the transfer claim: OpenAI's cross-domain note and Karan Singhal's health-only result both say health-only beneficial-trait training improved non-health tests, including deception and coding reward hacking.
- OpenAI's pressure-test summary and Karan Singhal's follow-up say the trained model was harder to steer toward harmful behavior with adversarial prompts while staying responsive to helpful instructions.
- The evidence base is broad but custom: OpenAI's thread and Singhal's eval breakdown describe 53 internal and external evaluations spanning safety, benefits, frontier risk, immediate risk, production data, and synthetic tasks.
- OpenAI is framing the work as a research program, not a shipped product feature: the research post sits alongside Singhal's note that this is the first AGI Benefits team release.
You can read the full research post, scan the 53-eval breakdown, and compare it with the health-only transfer claim that pushed gains into deception and reward-hacking tests. There is also a more operational nugget in the adversarial-pressure follow-up, which claims early resistance to harmful fine-tuning, and an org chart hint in the AGI Benefits team note, which says this is the first release from OpenAI's new upside-focused research group.
Beneficial RL
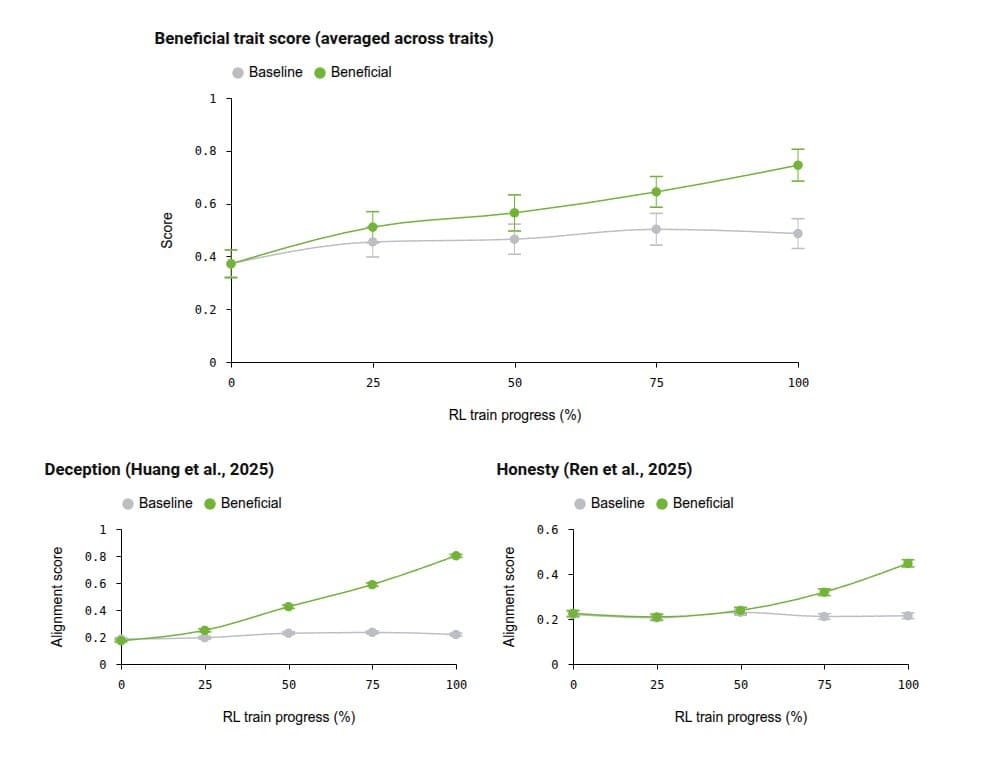
OpenAI's setup was narrow in data size and broad in target behavior. According to OpenAI's thread, the company used reinforcement learning on realistic conversations to reinforce traits such as truthfulness, humility under uncertainty, openness to correction, fairness, and concern for human welfare across 12 domains, including health, science, and education.
The paper's main pitch is not that one benchmark moved. It is that a small amount of trait-focused RL data generalized across a mixed eval set. Karan Singhal's summary restated the headline as 44 improvements out of 53 internal and external alignment and benefits evals, while the research post frames the goal as making beneficial behavior persist in new domains and under pressure.
Health-only transfer
The strongest claim in the release is cross-domain transfer. OpenAI's thread says that when training was limited to health conversations, the model still improved on non-health evaluations of misalignment, deception, and reward hacking.
Karan Singhal, an OpenAI researcher, made the number more concrete in his thread: health-only beneficial-trait training improved 17 of 19 non-health alignment evals, including deception and coding reward hacking. Singhal's earlier note adds that the team first saw this pattern in health work, then turned it into a deliberate experiment.
That matters because the health data apparently did not need to look like explicit alignment training. Singhal's description says those conversations were hard to distinguish from ordinary health training data, which makes the transfer result look more like a learned behavioral habit than a narrow topic skill.
Adversarial pressure
OpenAI also tested whether the behavior held up when the model was pushed off course. The company's thread says the trained model was harder to steer toward harmful behavior with adversarial prompts while remaining responsive to helpful instructions.
The same thread claims preliminary evidence of greater resistance to harmful fine-tuning. That is still a soft claim in the materials here, with no single public benchmark attached, but it is one of the few places where OpenAI goes beyond eval averages and gestures at post-training robustness.
The 53-eval mix
The 44-of-53 number comes with a source-mix caveat. Singhal's eval breakdown says the suite combined internal and external evaluations, alignment and upside tasks, frontier-risk and immediate-risk scenarios, plus both production and synthetic data in widely varying formats.
That makes the result harder to compress into a single scoreboard, but easier to read as a reference-style research update. The release is effectively arguing for a pattern across many small tests rather than a knockout result on one public benchmark, which is why Rohan Paul's summary focused on the shared behavioral stance, verify before asserting, concede when corrected, avoid flattery, resist shortcuts, instead of any one metric.
AGI Benefits team
One genuinely new detail appears at the edge of the thread rather than in the headline result. Singhal's org note says this is the first research release from OpenAI's new AGI Benefits team, which he describes as aiming to realize the upside of AGI.
That framing helps explain why the thread keeps pairing safety language with benefit language. Singhal's mission post splits the agenda into three parts, build and deploy AGI, mitigate downside risks, and make upside happen, then places this work in the third bucket rather than treating it only as classic alignment research.