OpenRouter launches Fusion API with DRACO panel tests at 1% of Fable
OpenRouter launched Fusion, a server-side panel API that fans prompts to multiple models, judges the outputs, and returns one synthesized answer. The company said DRACO landed within 1% of Fable at roughly half the price, but the published evals do not cover long-horizon tasks.
TL;DR
- OpenRouter launched Fusion as a server-side panel API that can be called with the
openrouter/fusionmodel slug or exposed as anopenrouter:fusiontool, according to OpenRouter's launch thread and the official docs. - On OpenRouter's DRACO run, a budget panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro landed at 64.7%, which OpenRouter's benchmark post and OpenRouter's thread both place within 1% of Fable 5's 65.3% while costing about half as much.
- The pipeline is straightforward: panel models run in parallel with search and tool access, a judge extracts consensus and contradictions, and a synthesizer writes the final answer, per OpenRouter's architecture explainer and the Fusion server tool docs.
- The eval story is narrower than the headline: OpenRouter used DRACO, a 100-task deep research benchmark, and later said in its FAQ update and follow-up tweet that it has not yet benchmarked long-horizon tasks.
- The launch immediately drew one implementation complaint, because teortaxesTex's API log post claimed a cheap-model Fusion run still called Opus 4.8 as judge, while the official docs say judge and panel selection are configurable.
You can read the full launch post, inspect the server tool docs, and poke at the Fusion playground. The weirdly useful detail is that OpenRouter says roughly three quarters of Fusion's lift came from synthesis rather than model diversity OpenRouter. The more important caveat is that the headline score came from DRACO only, and OpenRouter later singled out long-horizon work as the missing comparison OpenRouter.
Fusion
OpenRouter shipped Fusion as a compound model wrapper, not a new base model. The core promise is one API call that fans a prompt out to multiple models, compares the outputs, and returns a fused answer.
The launch materials describe three entry points:
model: "openrouter/fusion"for the model alias, per the launch post{ "type": "openrouter:fusion" }insidetools, per OpenRouter's tool example- The Fusion playground, which exposes Quality, Budget, and Custom presets
The product page also shows what OpenRouter considers the default quality setup: Claude Opus Latest, OpenAI GPT Latest, and Google Gemini Pro, with an auto fuse setting on top of them.
DRACO
The benchmark headline came from DRACO, Perplexity's deep research eval. According to the DRACO paper, it spans 100 tasks across 10 domains and grades outputs against task-specific rubrics covering factual accuracy, breadth and depth, presentation quality, and citation quality.
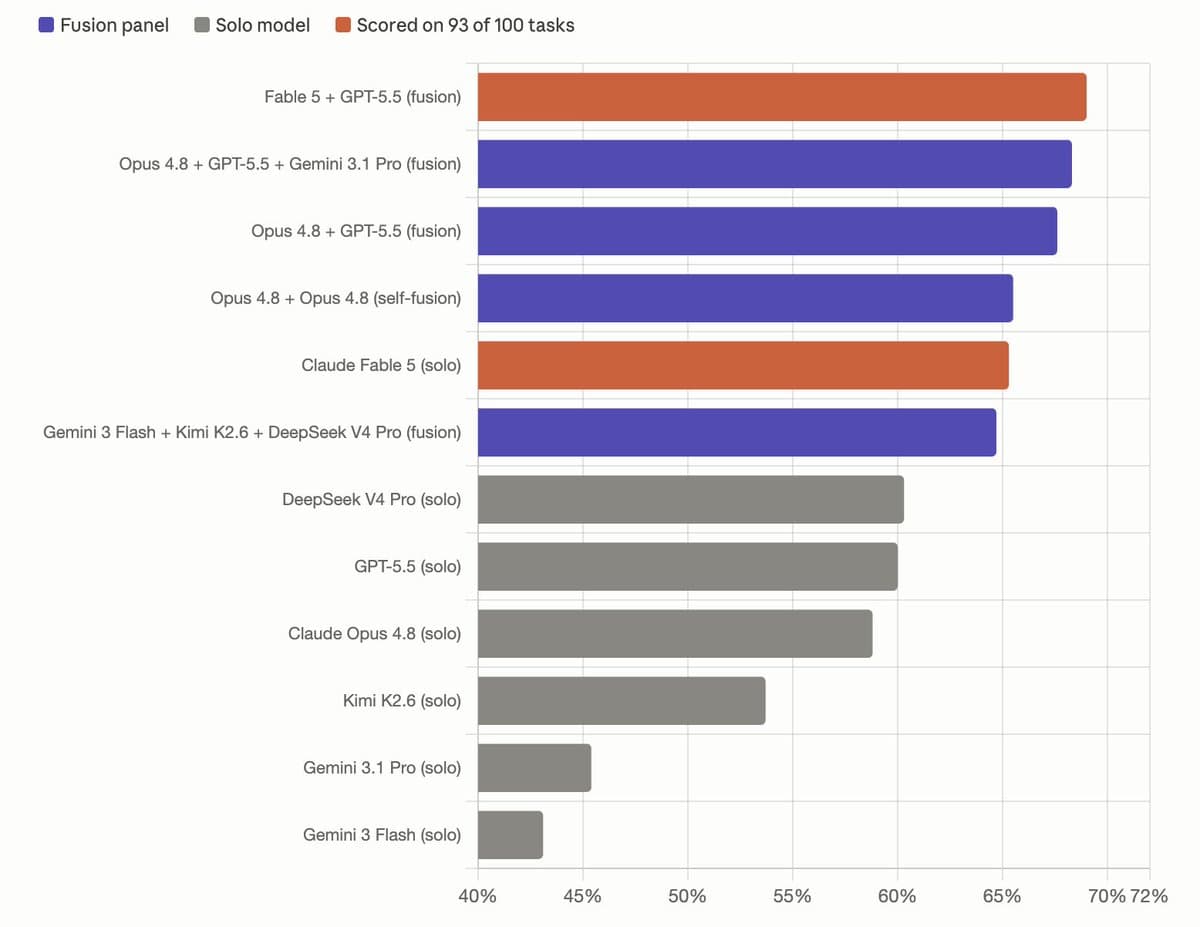
OpenRouter's published table in the official announcement is the part engineers will save:
- Fable 5 + GPT-5.5, synthesized by Opus 4.8: 69.0%
- Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro, synthesized by Opus 4.8: 68.3%
- Opus 4.8 + GPT-5.5, synthesized by Opus 4.8: 67.6%
- Opus 4.8 + Opus 4.8, synthesized by Opus 4.8: 65.5%
- Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro, synthesized by Opus 4.8: 64.7%
- Solo Fable 5: 65.3%
- Solo GPT-5.5: 60.0%
- Solo Opus 4.8: 58.8%
One buried footnote in the blog post matters. OpenRouter says 7 of the 100 DRACO tasks were not completed by Fable 5 because content filters blocked execution, so Fable's 65.3% score reflects 93 scored tasks rather than the full set.
Synthesis
OpenRouter says the main lift came from the fusion layer itself. In OpenRouter's ablation post, the company estimates roughly three quarters of the gain came from synthesis and one quarter from diversity.
The docs and launch post break the pipeline into distinct stages:
- Fan the prompt out to a panel of models in parallel
- Give each panel model
web_searchandweb_fetch, and in the benchmark setup alsobash, per the FAQ update - Have a judge produce structured analysis: consensus, contradictions, partial coverage, unique insights, blind spots
- Let the calling model write the final answer from that analysis
The self-fusion result is the sharpest clue about what OpenRouter thinks it built. In the official announcement, Opus 4.8 fused with itself reached 65.5%, up from solo Opus 4.8 at 58.8%.
Caveats
OpenRouter spent unusual effort documenting eval contamination. In its follow-up thread, the company said panel models with web search started surfacing the DRACO rubric online, so it excluded those domains and reran the benchmark.
The launch post adds two more limits:
- OpenRouter used Gemini 3.1 Pro Preview as the DRACO judge rather than the paper's Gemini 3 Pro, so the scores are not directly comparable to the paper's published numbers
- DRACO is text-only and English-only, and the paper reports that absolute scores can shift materially with judge choice
OpenRouter also narrowed its own headline after launch. In the FAQ section of the blog post and a later reply, the company said it has only evaluated one deep research benchmark so far, and that benchmark did not include long-horizon tasks where Fable was "extremely impressive."
Defaults
The first community complaint was about what Fusion actually calls under the hood. teortaxesTex's API log post said a cheap open-model configuration still invoked Opus 4.8 as judge and offered no way to disable it.
The official docs draw a more granular picture, but they also explain why this got confusing fast:
- The
openrouter:fusionserver tool is still in beta - The server tool's
analysis_modelsdefault to a quality preset of frontier models - The server tool's
modelfield controls the judge and defaults to the outer model handling the request - The model alias and plugin use the same underlying pipeline, but the alias auto-injects a default panel, per the launch FAQ
- Inner Fusion calls carry an
x-openrouter-fusion-depthheader so panel and judge models cannot recursively invoke Fusion, per the docs