Opus 4.7 users report instruction-following misses, refusals, and ~1.3x token burn a day after launch
A day after Opus 4.7 launched, users are surfacing adaptive-thinking misses, surprise refusals, and higher token use. For engineers, recheck prompts, costs, and 4.6 fallbacks while Anthropic patches bugs and lifts limits.
TL;DR
- Anthropic shipped Opus 4.7 with adaptive thinking docs, a new xhigh effort tier, and task budgets, but RayFernando1337's UI screenshot and Ethan Mollick's thread quickly turned the launch into a fight over a missing manual override for thinking.
- The migration note in Nathan Lambert's tokenizer screenshot says the same input can map to roughly 1.0 to 1.35x more tokens, and Boris Cherny later confirmed Opus 4.7 uses more thinking tokens and that Anthropic raised subscriber limits to compensate.
- User reports split hard by workload: Jeremy Howard said 4.7 was the first model that "gets" his work, while kimmonismus and Gergely Orosz described instruction-following regressions, combative replies, and a return to 4.6.
- Anthropic spent the next day patching. Alex Albert said many launch-day bugs were fixed, Ethan Mollick reported adaptive thinking started triggering more often, and the Claude Code 2.1.112 changelog shipped an auto mode fix tied to Opus 4.7 availability.
You can read Anthropic's launch post, the adaptive thinking docs, and Anthropic's Claude Code best-practices post. There is also a live Hacker News thread where commenters compared 4.7 against Codex, complained about latency, and shared settings tweaks that Anthropic later partly addressed.
Adaptive thinking
Anthropic made adaptive thinking the center of the release, not an optional extra. The docs say Opus 4.7 supports only thinking.type: "adaptive", while the older fixed-budget mode is gone for this model in both the app and API.
That design choice landed badly outside coding. According to Mollick's thread, Opus 4.7 often chose low effort on analysis, writing, and research tasks, which also meant less tool use and web search. Yuchenj_UW's screenshot shows the web app exposing only an adaptive toggle, while the adaptive thinking docs state that Opus 4.7 rejects the old explicit thinking budget mode outright.
By the next day, Anthropic appears to have retuned the router. Mollick's follow-up said adaptive thinking was triggering much more often and materially improved non-coding output quality, although he added that rough edges remained.
Token burn and limits
The buried migration note mattered more than the price sheet. Anthropic kept Opus list pricing flat, but the upgrade guide shown in Nathan Lambert's screenshot says the tokenizer change can push the same input to 1.0 to 1.35x more tokens, and that Opus 4.7 also produces more output tokens at higher effort levels.
That showed up fast in real usage. bridgemindai's usage screenshot says three prompts consumed 13 percent of a Max session, and bridgemindai's earlier post hit 100 percent session usage within hours of launch. Independent spot checks like badlogicgames' token-count example found a README climbing from 1,091 tokens on Opus 4.6 to 1,454 on 4.7.
Anthropic acknowledged the cost pressure in two steps. First, Boris Cherny said Opus 4.7 uses more thinking tokens and that limits were increased for all subscribers. Then trq212's quick-fix note and Alex Albert's bug-fix post suggested some of the worst rate-limit behavior on day one was a bug, not just the new model profile.
Refusals and safety bugs
The harshest reports were not about benchmarks. They were about normal tasks getting flagged, paused, or second-guessed.
Lech Mazur's Connections example shows Opus 4.7 pausing a word-puzzle prompt behind extra safety checks. Theo's screenshot shows the model treating a system reminder as prompt injection while reviewing a normal personal site. Later, chetaslua's hallucination example highlighted a contradictory yes-no answer inside Claude Code itself.
Anthropic now says at least part of this was a launch bug. the ClaudeDevs repost says some malware-style warnings on ordinary code edits came from Anthropic's side and were fixed, while Alex Albert broadly said many bugs that people hit on the first day were resolved.
The more structural issue is that refusals also started showing up in third-party eval chatter. Lech Mazur's Connections benchmark post counted refusals as failures, and Lech Mazur's later reply said he was still seeing a high refusal rate on benchmarking and creative-writing prompts even after the first round of fixes.
Instruction following
A lot of the anger came from a narrower complaint: 4.7 was more literal, but not always more obedient. Anthropic's own migration guidance, visible in nrehiew_'s screenshot, says Opus 4.7 is more literal and direct than 4.6, especially at lower effort levels.
That wording lines up with the field reports. nummanali called 4.7 an instruction follower that no longer explores, Gergely Orosz described it as combative in conversational work, and pvncher argued that 4.7 second-guessed prompts instead of carrying them out. The best independent summary may be the Every vibe check, which framed 4.7 as sharper on well-specified work and worse at reading between the lines.
The split was real, not universal. Jeremy Howard said 4.7 finally felt aligned with how he works, and Emad Mostaque said it was great for design but that he reverted to 4.6 extended thinking for most other tasks.
Benchmarks cut both ways
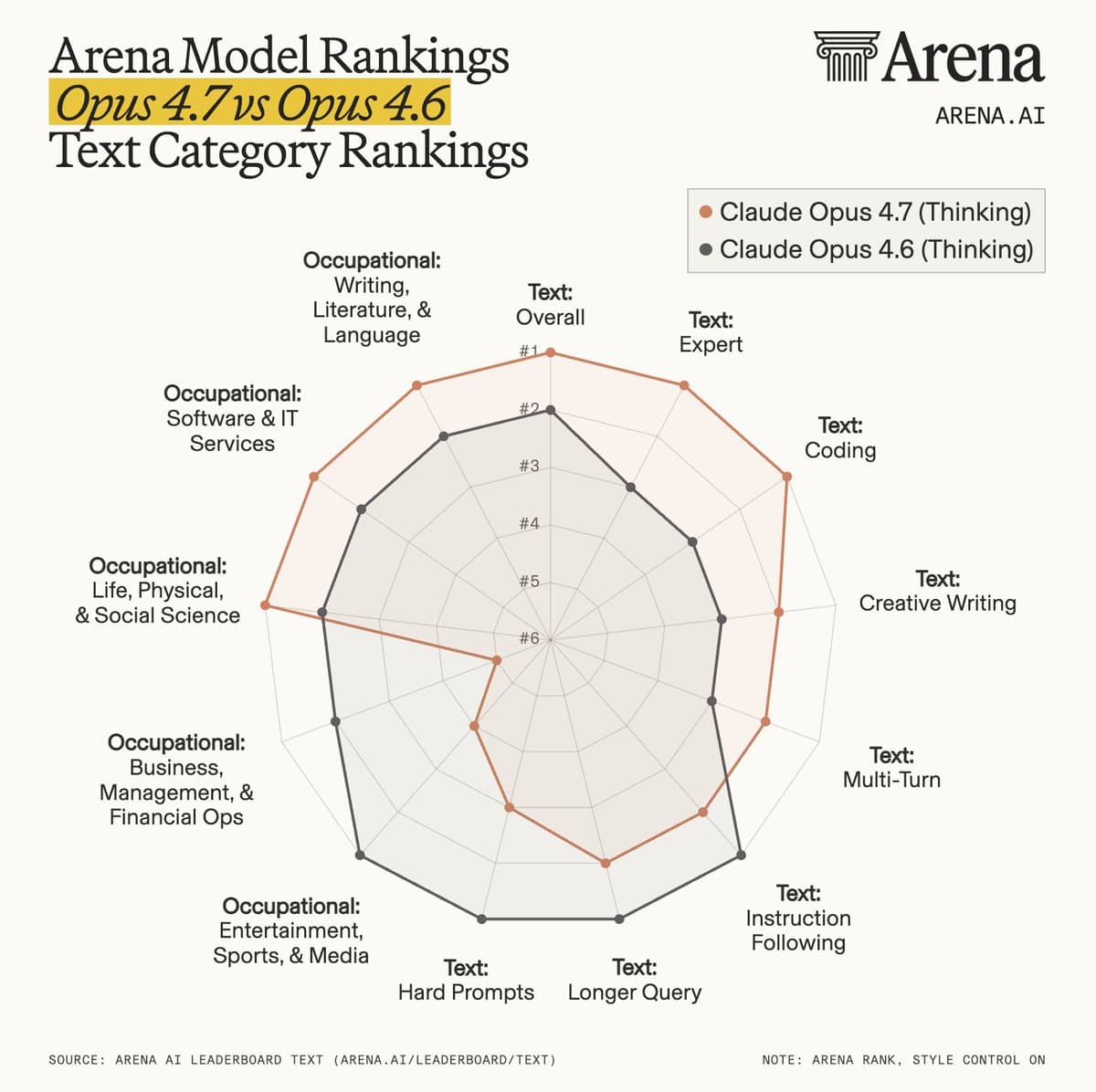
Anthropic's launch chart was strong on coding, tool use, and vision, per Anthropic's benchmark card, and outside evaluators added more fuel. Artificial Analysis' model page and Artificial Analysis put Opus 4.7 at the top of GDPval-AA and tied at the top of the firm's overall intelligence index, while Arena's Code Arena post and Arena's Text Arena post pushed it to the top of Arena leaderboards.
But the weak spots were unusually visible for a flagship Opus release.
- Long context: kimmonismus' MRCR chart and nrehiew_'s post both flagged a steep drop from Opus 4.6 on MRCR at 256k and 1M tokens.
- SimpleBench: AiBattle_ put Opus 4.7 at 62.9 percent, below Opus 4.6 at 67.6 percent.
- Thematic generalization: Lech Mazur reported 80.6 to 72.8 deterioration depending on effort configuration, plus much higher completion token counts.
- BullshitBench: Peter Gostev said 4.7 underperformed the 4.6 family, and that max-thinking 4.7 did worse than non-thinking 4.7 on clear pushback.
That is why the public reaction felt incoherent. The model could look like a coding monster on Arena and still frustrate people doing long-context research, puzzle-style reasoning, or loosely specified product work.
Claude Code patches
The fastest-moving part of the rollout was Claude Code. Anthropic launched /ultrareview, expanded auto mode, raised the default effort level to xhigh, and published a whole best-practices post for Claude Code that effectively told users to change how they prompt and supervise the model.
The practical changes clustered into a few buckets:
- New commands and modes: Anthropic's feature thread added
/ultrareview, and Boris Cherny's tips thread pushed auto mode as the right surface for long-running work. - New defaults: Matt Pocock's screenshot says Claude Code's default effort moved from medium to xhigh, which helps explain why some users saw more token burn before touching any settings.
- New bugs and fixes: ClaudeCodeLog says version 2.1.112 fixed the false "claude-opus-4-7 is temporarily unavailable" alert in auto mode.
- New workarounds: nummanali points to
claude --thinking-display summarizedfor missing thinking summaries, while the related GitHub issue tracks the VS Code extension regression.
Anthropic's own guidance is unusually explicit here. The best-practices post says to specify constraints in the first turn, use xhigh for serious agentic coding, and treat 4.7 as a delegation-first model rather than a line-by-line pair programmer. Christmas came early for coding agent nerds, but only if they were willing to retool their harness.
GDPval-AA fight
One new fight landed after most of the launch bugs. Artificial Analysis made GDPval-AA the cleanest case for Opus 4.7's leadership, with Artificial Analysis claiming a 1,753 Elo score, a 79 Elo lead over the next closest models, and lower overall run cost than Opus 4.6 despite the tokenizer change.
But Ethan Mollick's critique argues GDPval-AA is not a trustworthy substitute for the original GDPval because it uses public questions and Gemini 3.1 as the judge, without evidence that the result tracks expert human grading. Mollick's follow-up called it gameable and said the field still lacks trustworthy measures of AI ability.
That leaves Opus 4.7 in a very 2026 place. It has enough benchmark wins and enough hands-on complaints that the scoring story now depends almost as much on the harness and judge as on the model itself.