GLM-5.2 adds Perplexity Agent API and Droid support on Baseten at >280 TPS
GLM-5.2 added Perplexity Agent API, Droid, and more hosting options, while Baseten reported over 280 TPS and sub-0.8s TTFT. Builders should watch the cost and benchmark data as it moves into production agent stacks.
TL;DR
- GLM-5.2 moved from benchmark curiosity into real agent stacks over the weekend, with AravSrinivas announcing Perplexity Agent API support, FactoryAI showing Droid support hosted by Fireworks, Ollama reporting a capacity doubling for GLM 5.2, and Baseten advertising hosted inference.
- On third-party evals, Artificial Analysis ranked GLM-5.2 at #3 overall on GDPval-AA and Artificial Analysis placed it on the AA-Briefcase cost-performance frontier, while WesRoth's DeepSWE snapshot still showed it behind GPT-5.4 xhigh at 52%.
- In hands-on coding runs, cline's Cline repo test found GLM used more tokens and more tool calls than Opus 4.8, but still cost less and returned the cleaner fix.
- Speed is part of the pitch now: Baseten claimed more than 280 tokens per second and under 0.8 second TTFT, while wafer_ai posted 222 output tok/s and 12.6 second end-to-end latency and Modal showed FP8 throughput data.
- The caveats stayed visible in the same launch window, because browser_use said GLM-5.2 does not support images, mattpocockuk described unusually long reasoning traces, and tomgreenwald questioned whether local 2-bit quantization is ready for meaningful work.
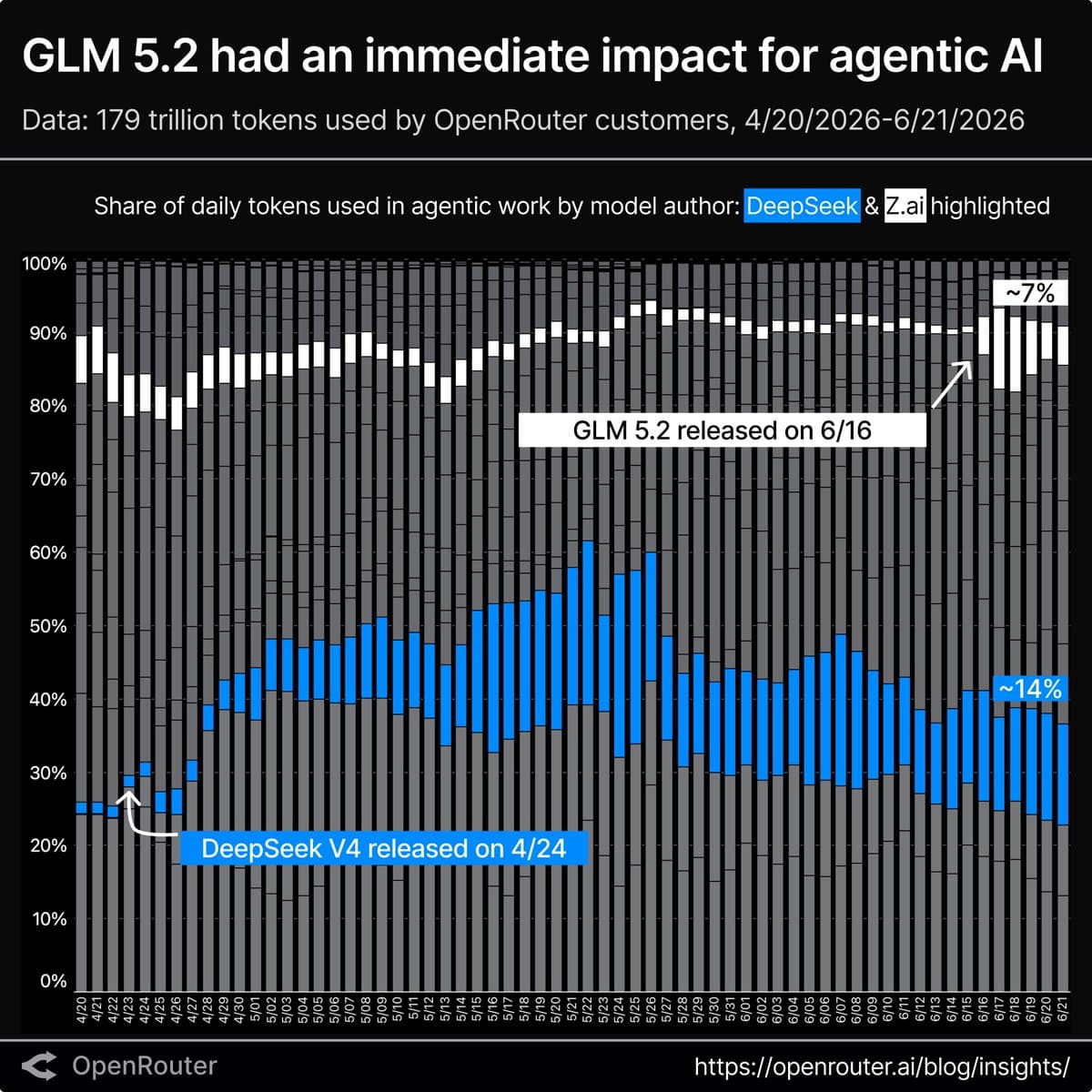
You can skim Artificial Analysis' GDPval-AA chart, open the AA-Briefcase launch article, try the Baseten deployment, and check how quickly providers rushed it out in Droid, the Perplexity Agent API, and Ollama Cloud. One of the stranger tells came from browser_use, which paired the text-only model with multimodal QA subagents so it could inspect its own website output indirectly. Another came from OpenRouter's uptake chart, where GLM 5.2 ramped faster than most open-weight launches.
Hosting rollout
The fastest story here was distribution. Within days, AravSrinivas said GLM was supported in the Perplexity Agent API, FactoryAI put it into Droid via Fireworks, and Ollama said it had already doubled GPU capacity to handle usage.
A few more surfaces filled in around that core rollout:
- Baseten offered hosted inference and pitched it on latency.
- Modal posted FP8 performance data for agentic multi-turn runs.
- browser_use added it to BrowserCode for cheap browser tasks.
- Yuchenj_UW said they were using an internal Databricks endpoint.
The notable bit is not that providers added another open model. It is that GLM-5.2 showed up across agent harnesses, browser agents, cloud endpoints, and hosted coding tools almost immediately.
Benchmark positions
The strongest external benchmark evidence came from Artificial Analysis. Artificial Analysis put GLM-5.2 at 1524 Elo on GDPval-AA, good for #3 overall behind Claude Fable 5 and Claude Opus 4.8, and ahead of GPT-5.5 xhigh at 1509.
Artificial Analysis also gave it a strong cost-performance showing on AA-Briefcase:
- AA-Briefcase said GLM-5.2 cost about $2.40 per task.
- The same AA-Briefcase result placed it within 90 Elo points of Claude Opus 4.8 while costing 65% less.
- GDPval-AA reported about 31 turns per task across 1,999 matches, which matters because these were multi-turn agentic tasks, not one-shot prompts.
The ceiling still looked lower on software-heavy evals. WesRoth's DeepSWE post showed GLM-5.2 at 44%, ahead of the Gemini models in that test but behind GPT-5.4 xhigh at 52%, with 129 average agent steps and 78,000 output tokens.
Coding harness behavior
The most useful hands-on report came from cline, because it used the same harness and the same real bug for both models. GLM-5.2 fixed the issue for $0.41, while Opus 4.8 cost $0.81. Opus finished faster, but GLM returned the cleaner outcome.
cline's breakdown is more informative as a list than as a victory lap:
- Cost: GLM $0.41, Opus $0.81.
- Tokens: GLM 1.1M, Opus 660K.
- Runtime: GLM 4.7 minutes, Opus 1.6 minutes.
- Tool calls: GLM 28, Opus 12.
- Result: GLM cleaned up dead code and verified the build; Opus left type errors that passed tests but broke the production build.
That pattern matches two separate commentary threads. cline's follow-up said they saw the same verify-before-complete behavior in repeated anecdotal tests, while teortaxesTex's research benchmark screenshot showed GLM unusually strong on research-style tasks, including optimizer design and molecular gap prediction, at very large token budgets.
Throughput and demand
Provider competition turned into a second benchmark layer. Baseten claimed more than 280 TPS and less than 0.8 second time to first token, which is the most aggressive speed claim in the evidence pool.
Other providers published enough numbers to show the serving market moving around GLM-5.2:
- wafer_ai claimed the fastest listed endpoint on Artificial Analysis at 222 output tok/s, with 12.6 second end-to-end response time.
- wafer_ai's pricing reply quoted $1.20 per million input tokens, $4.10 per million output tokens, and $0.20 cache pricing.
- Modal showed FP8 throughput data on 8xB200 for agentic multi-turn workloads.
- OpenRouter said GLM 5.2 uptake was unusually fast relative to most open-weight launches.
The demand side showed up in the replies as much as the headline posts. wafer_ai and wafer_ai both said they were adding compute as fast as possible, and Ollama said it had already doubled US-based GPU capacity.
Missing vision and long thinking traces
The tradeoffs were unusually consistent across unrelated users. browser_use said flatly that GLM-5.2 does not support images, and browser_use's website-design run worked around that by pairing it with multimodal QA subagents that reviewed the rendered site, judged aesthetics, and fed targeted fixes back to GLM.
The other recurring caveat was token burn:
- mattpocockuk reported nearly 220K thinking tokens in three turns while using pi.
- anderslie argued that open models, including GLM 5.2, often overthink in agent harnesses and said their provider forcibly constrains reasoning length.
- cline's bug test also fits that shape, because GLM spent more tokens and more steps verifying work before finishing.
That behavior helps explain the split personality in the current GLM story. It is cheap enough that teams keep reaching for it, but it is not yet a neat drop-in replacement for closed models on every surface.
Local use is still a soft spot
One more gap appeared after the hosting rush: the model may be cheap, but "can run locally" and "can run locally for meaningful work" were not the same claim. ai_for_success liked GLM partly because it can run locally, while tomgreenwald pushed back that 2-bit quant results with 82% top-1 accuracy compound errors too quickly for serious tasks.
That leaves an odd end state for June 23. The cloud story is already mature, because Perplexity, Droid, Baseten, BrowserCode, Modal, Wafer, OpenRouter, and Ollama all moved quickly. The local story still looks unfinished.