
Google Gemini 3 Pro rolls out in AI Studio – $2 in, 1M‑token video analysis
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google’s Gemini 3 Pro is actually live in AI Studio and showing up in the Gemini web app, which means you can ship against it today. Leaked pricing points to 200K tokens or less at $2 in and $12 out, and higher tiers at $4 in and $18 out, with a Jan 2025 cutoff. The headliners: agentic coding, Generative UI/Visual Layout, and a 1M‑token context for long‑video analysis.
What’s new since our weekend sightings: real agent demos. Antigravity spins up coding agents that edit a Supabase backend, drive a browser, and close bugs end‑to‑end, while Generative UI assembles tappable layouts and mini‑apps directly in chat. The Deep Think preview posts 45% on ARC‑AGI‑2 (ARC Prize verified), 88% on ARC‑AGI‑1, and 93.8% on GPQA Diamond, but access is capped to safety testers; Pro lands around 31% on ARC‑AGI‑2. Run agents in sandboxed accounts and require diffs—still a sharp tool, not autopilot.
Early signals look strong: one creator reports 72.7% on ScreenSpot‑Pro and community arenas place Gemini 3 Pro at or near the top across text, vision, and webdev. Per Andrej Karpathy, treat public leaderboards as hints, not verdicts—do a week of A/Bs on your workload, then switch defaults if it holds.
Feature Spotlight
Gemini 3 for creators: agents, UI, and rollout
Gemini 3 Pro + Deep Think bring agentic coding and Generative UI to creators, with AI Studio access and Antigravity demos—raising the bar for building apps, tools, and visuals directly from a prompt.
Massive cross‑account story: Gemini 3 Pro lands with agentic coding (Antigravity), Generative UI/Visual Layout, 1M‑token video analysis, and AI Studio access. Mostly hands‑on demos, pricing leaks, and early benchmark effects.
Jump to Gemini 3 for creators: agents, UI, and rollout topicsTable of Contents
✨ Gemini 3 for creators: agents, UI, and rollout
Massive cross‑account story: Gemini 3 Pro lands with agentic coding (Antigravity), Generative UI/Visual Layout, 1M‑token video analysis, and AI Studio access. Mostly hands‑on demos, pricing leaks, and early benchmark effects.
Deep Think preview posts 45% on ARC‑AGI‑2; limited access for now
Gemini 3 Deep Think preview hit 45% on ARC‑AGI‑2 (ARC Prize verified), with 88% on ARC‑AGI‑1 and 93.8% on GPQA Diamond, while Pro clocks 31% on ARC‑AGI‑2 ARC‑AGI results. Access is currently restricted to safety testers, with a planned rollout to Ultra subscribers after additional checks Safety testers note.
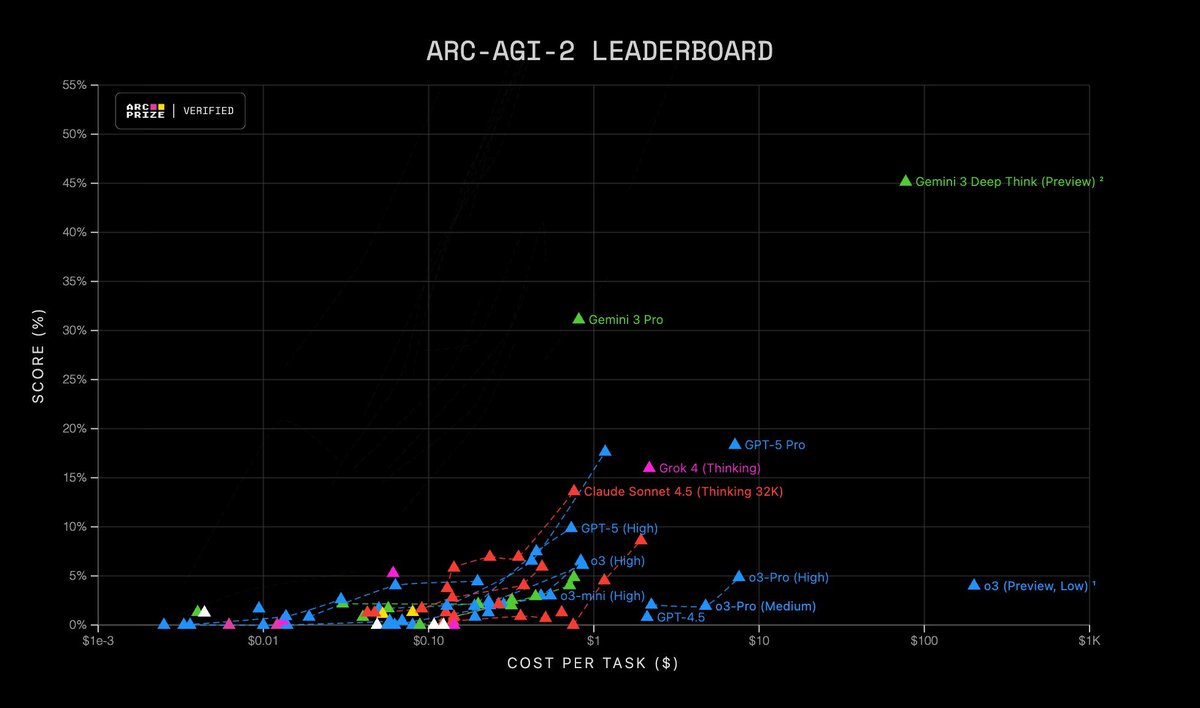
The point is: this narrows the gap on long‑horizon reasoning. It’s pricey per task in preview, so budget non‑trivial runs carefully, and keep Pro as the default until the mode opens more broadly.
Gemini 3 Pro rolls out in AI Studio and Gemini web
Google began rolling out Gemini 3 Pro to AI Studio, with creators reporting live access, and it’s also appearing on the Gemini web app. This moves the model from speculation to daily use for builders. Following up on UI strings, early hints in app strings now translate to broad availability. See creator confirmations and a global montage in the launch clips AI Studio check and Web app check.
So what? You can start vibe‑coding apps, testing multimodal prompts, and kicking the tires on the new agentic behaviors today. Expect staggered enablement by account and region, so keep rechecking the model picker in AI Studio Global rollout.
Generative UI lands: dynamic layouts, mini‑apps, and 1M‑token video analysis
Creators are seeing Gemini 3 assemble visual layouts and bespoke tools on the fly—tour plans with tappable cards, simulators, and code‑backed mini‑apps. One demo highlights a “Visual Layout” mode, and another shows it generating calculators and physics visualizations directly in the response Visual layout explainer Tool coding demo. The model also touts a 1M‑token context for long‑video analysis Visual layout explainer.
Try concrete, outcome‑first asks (“compare three AAA loans”) and let it decide tables vs. widgets. For education and research explainers, use the three‑body sim style prompts to force visual reasoning Three body sim.
Google’s Antigravity IDE demos agentic coding, browser control, and live fixes
Multiple demos show Antigravity spawning agents that test apps, control the browser, make Supabase changes, and even play a pinball sim—alongside whiteboard and flight‑tracker examples Early tester thread Demo set. One creator reports the agent found a bug, edited the backend, and resolved the issue end‑to‑end without manual glue.
Here’s the catch: oversight still matters. Run in isolated accounts, watch permission scopes, and expect occasional mis‑edits. But for prototyping and QA loops, this compresses hours into minutes.
Gemini 3 Pro climbs to #1 across major Arena leaderboards
Community leaderboards show Gemini‑3‑Pro taking top slots across Text, Vision, and WebDev, edging Grok‑4.1, Claude‑4.5, and GPT‑5 variants Arena overview. Creators also shared LMArena/WebDev placements and site sightings after the model went live Ranking video.
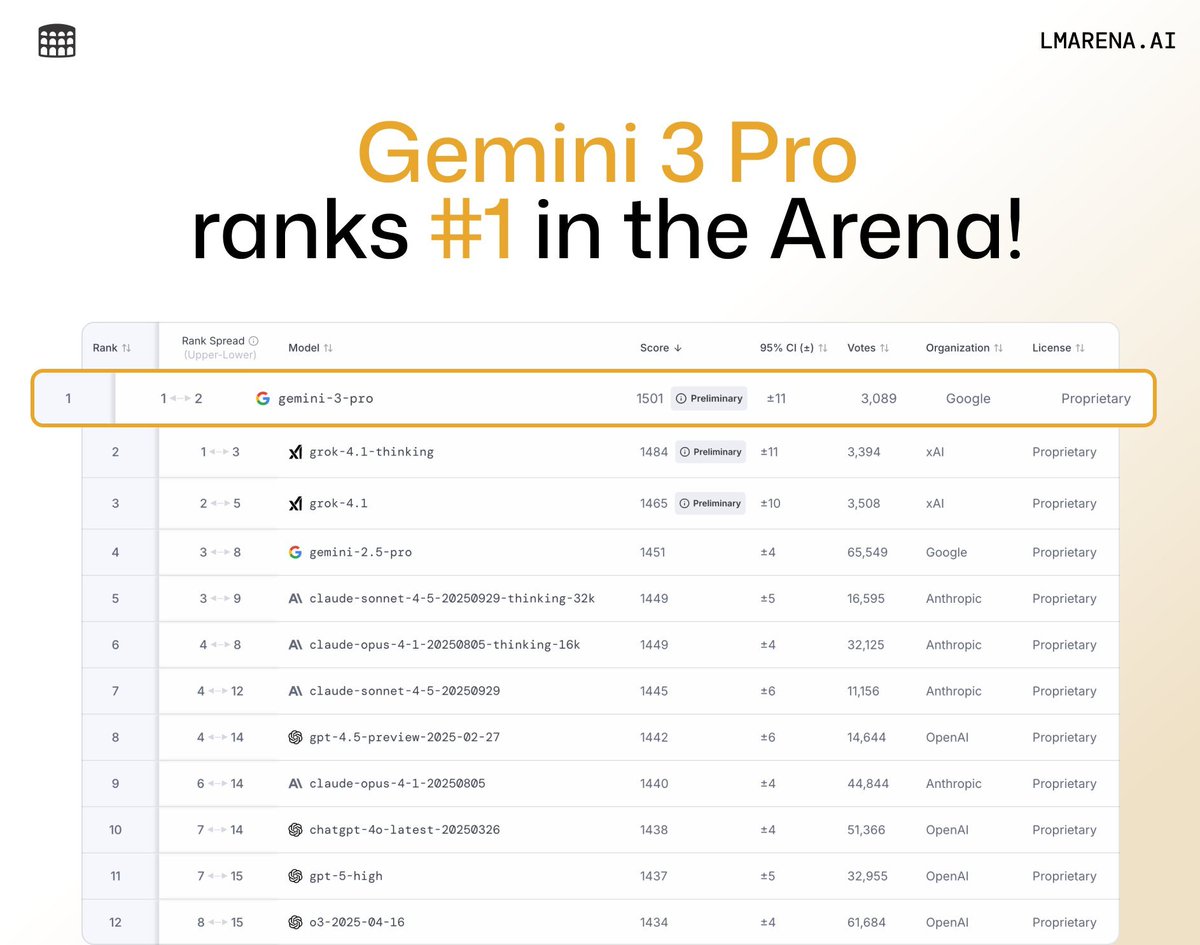
- Text Elo: ~1,501 (reported) and big WebDev gains vs 2.5 Arena overview
- Visibility: also flagged as available on the Gemini web app Web app check
Use this to prioritize your A/B queue. Then verify on your tasks before switching defaults.
Leaked Gemini 3 Pro pricing and docs detail token tiers, Jan 2025 cutoff
Pricing screens circulating show two token tiers: ≤200K tokens at $2.00 in / $12.00 out, and >200K tokens at $4.00 in / $18.00 out, with a knowledge cutoff listed as Jan 2025 Pricing details. Docs briefly surfaced as “Confidential” and then 404’d for some users, suggesting a staged docs rollout Docs 404.

For teams budgeting experiments, those output rates matter. The official endpoint path appeared under Google’s API docs before vanishing—keep an eye on the re‑published page when it stabilizes API docs.
“Vibe coding” in practice: custom instructions and a one‑prompt app build
Builders are sharing prompt discipline for Gemini 3 Pro: plan first, debug elegantly, create closed‑loop tests, and fully own UI checks—then let the model iterate internally before handing back Prompting guide. In a separate demo, a full interactive app was generated from a single high‑level prompt in one shot Vibe coding demo.
Actionable today: encode those instructions in the system slot, ask for self‑tests, and require diffs for changes. It reduces babysitting and yields steadier builds.
Karpathy urges hands‑on model tests amid public benchmark spikes
Andrej Karpathy calls Gemini 3 a tier‑1 daily driver on personality, writing, coding, and humor—but warns that public benchmarks can be nudged via adjacent data, advising people to A/B models directly Karpathy notes. He shared a funny exchange where the model denied the 2025 date until search tools were enabled, then relented Round‑up post.

The takeaway: keep your own eval set close to your workflow. Rotate models daily for a week before picking a default.
Ecosystem moves: Lovart, Kilo Code, and Verdent adopt Gemini 3
Third‑party tools are lighting up support: Lovart says Gemini 3 is live for UI design studies Lovart availability, Kilo Code shares internal coding scores (Gemini 3 Pro 72% vs Claude 4.5 54% vs GPT‑5.1 Codex 18%) Kilo Code test, and Verdent markets multi‑agent orchestration that runs parallel Gemini sessions with auto verify steps Verdent orchestration.
So what? The model is already where designers and engineers work. Try a small sprint inside one of these tools before migrating full pipelines.
Gemini 3 posts 72.7% on ScreenSpot‑Pro, hinting at stronger UI‑use skills
On the ScreenSpot‑Pro benchmark, a creator reports Gemini 3 at 72.7%, with the next best model at 36.2% Screenspot score. The claim, if it holds, suggests a faster path to robust computer‑using agents.
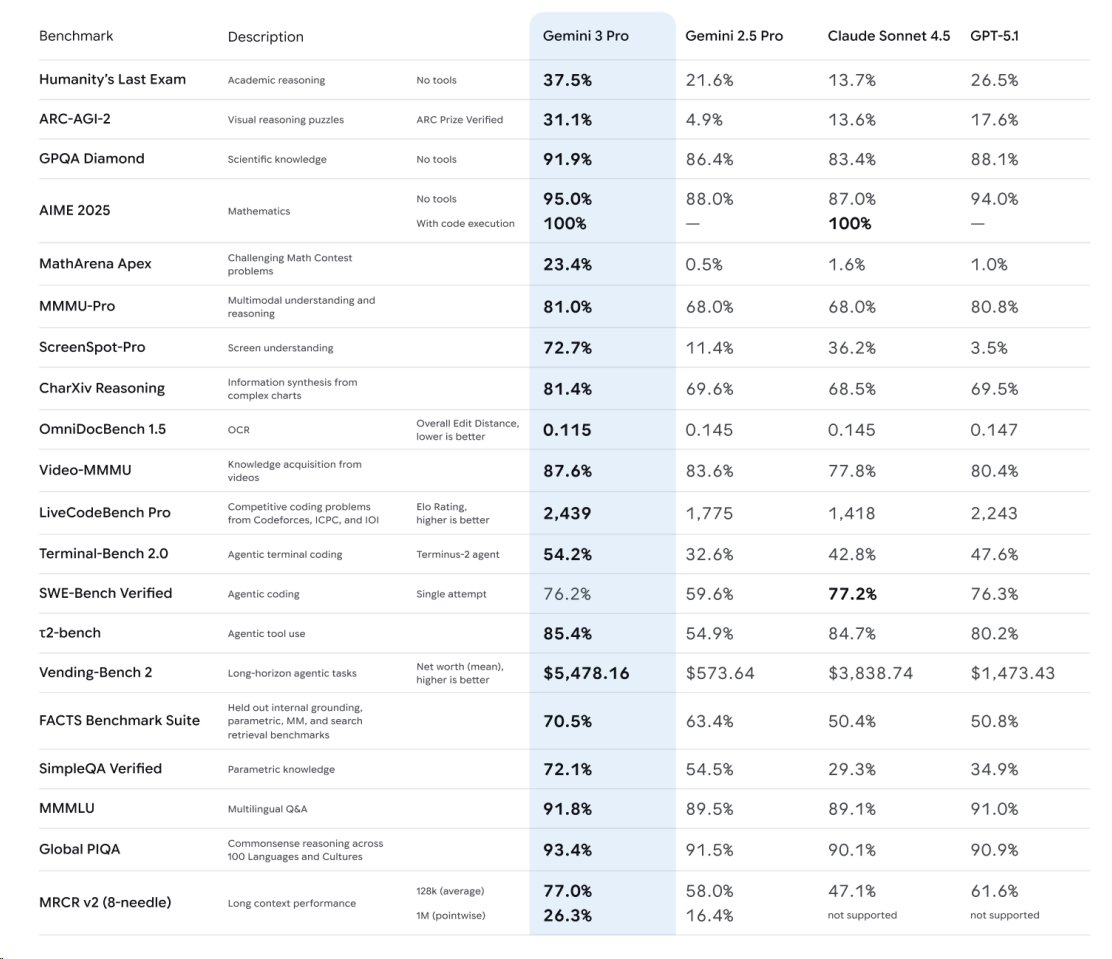
Treat it as directional until wider replications land. But for RPA‑ish tasks, route trials through Gemini 3 first and compare head‑to‑head.
🎬 Filmmaking in the wild: 30k‑ft ad, model face‑offs, controllable motion
Practical production wins and tool tests: a full airline ad made in 14 hours mid‑flight, creator comparisons of Grok/Kling/Veo, and new node‑level motion control in ComfyUI. Excludes the Gemini 3 launch (see feature).
A full Qatar Airways ad was made in 14 hours at 30,000 ft using AI tools
A creative team produced two Qatar Airways commercials mid‑flight in 14 hours by mixing Google/Starlink connectivity, Gemini for planning/assets, Figma for layout, Veo 3.1 to animate stills, and Suno for music; they delivered before landing project overview. They shot reference photos to match aircraft details reference photos, used clean camera‑move prompts to animate scenes in Veo 3.1 prompt example, and cut the final with a bespoke track made in Suno music workflow, wrapping with less than 15 minutes to spare final delivery.
Veo 3.1 turns stills into polished shots with simple camera‑move prompts
Creators show Veo 3.1 reliably animating single images into usable shots using terse directives like “photorealistic; slow left orbit; sip coffee; push‑in close‑up,” which keeps motion natural and avoids overacting prompt example. A separate roundup highlights Veo 3.1’s prompt adherence, precise audio‑visual alignment, and strong object‑level edits—useful when timing to music or correcting props Veo overview.
Adobe Firefly now auto‑scores your video with licensed music
Firefly’s new Generate Soundtrack analyzes your uploaded clip, proposes a fitting prompt, and returns four synchronized tracks; you can tweak vibe/style/tempo and re‑gen, then download stems or a scored video. It’s built on licensed content, so results are safe for commercial use feature overview. A step‑by‑step shows the full workflow from upload to selection and export workflow steps.
ComfyUI’s Time‑to‑Move adds controllable motion to Wan 2.2 pipelines
ComfyUI is hosting a deep dive on Time‑to‑Move (TTM), a plug‑and‑play technique to inject intentional, controllable motion into Wan 2.2—useful for precise pans, pushes, and character action beats deep dive session. There’s also a how‑to covering blockouts and motion intent for animating sequences inside ComfyUI tutorial video.

Grok, Kling 2.5 Turbo, and Veo 3.1 compared on emotional range
A side‑by‑side creator test compares Grok Imagine, Kling 2.5 Turbo, and Veo 3.1 on delivering nuanced, believable emotion across short scenes. The cut makes it easier for teams to pick a model per sequence—e.g., close‑ups needing micro‑expressions versus stylized affect model comparison.
Leonardo tests: when to reach for Sora 2, Veo 3.1, Kling 2.5, or Hailuo 2.3
LeonardoAI shared real‑project notes that map model strengths to tasks: Sora 2 for physics‑accurate, constraint‑respecting shots Sora summary; Veo 3.1 for tight prompt adherence, audio‑visual timing, and object edits Veo brief; Kling 2.5 Turbo for professional transitions and start→end frame control Kling summary; and Hailuo 2.3 for budget‑friendly runs that still look strong Hailuo summary. The reel is a handy cheat sheet for shot planning and budget routing model highlights.
🖼️ Photoreal textures, clean type, and reusable styles
Image tools skew toward fidelity and control today: ImagineArt 1.5 pushes pore‑level texture and correctly spelled typography; creators share reliable style refs. Mostly creator tests—few platform policy notes.
ImagineArt 1.5 shows pore‑level realism and clean, correctly spelled type
Creators report that ImagineArt 1.5 holds micro‑material detail (pores, fabrics, reflections), renders text crisply for posters/UX, follows complex prompts with low hallucination, and keeps fidelity when zoomed to pixels, following up on montage first looks. See claims on texture focus Feature thread, text accuracy Text example, prompt obedience Obedience claim, and a tight zoom test Zoom sample, with a place to try it in the studio ImagineArt image studio.
Midjourney paper‑sculpture sref 2499912115 locks a handmade cut‑paper look
A reusable MJ V7 recipe (--sref 2499912115) dials in a pop‑up book/cardboard diorama aesthetic for children’s editorial and stop‑motion‑style scenes, letting you inherit the look without verbose prompting Style recipe.

Grok Imagine gets portable style kits: token lexicon and prompt sets
Two community packs make Grok Imagine styling easier to repeat: a compact token list for editorial/retro looks (e.g., “Glitchwave,” “LomoChrome Metropolis”) Token list, plus a multi‑image prompt set others are remixing into consistent sequences Prompt set.

New MJ V7 recipe (sref 87144643) shared with chaos 22 and 3:4 output
A fresh Midjourney V7 setup—--sref 87144643, --chaos 22, --raw, --ar 3:4, --sw 500, --stylize 500—produces a consistent look creators can reuse across runs V7 prompt.

🧰 Design prototyping with AI: Figma Make, vibe‑coded apps
Applied UI/UX gains: early Figma Make tests show AI turning boards into functional prototypes with animations and backend hooks. Excludes the Gemini 3 launch (see feature); focuses on day‑one design workflows.
Figma Make tests Gemini 3 Pro for prompt-to-prototype builds
Figma enabled Gemini 3 Pro as an experimental model inside Make, with early runs turning a static board into a working prototype—SVGs, physics-style animations, and a Supabase hookup generated from a prompt Figma Make demo. Designers can toggle it in experimental settings and watch it map style shifts (Y2K chrome → brutalist) while keeping interactions intact.
One‑prompt UI tool for Nano Banana built in AI Studio
A creator used Gemini 3 in AI Studio to one‑shot an image‑model explorer: batch re‑runs, pending output states, keyboard binds, full‑size modal previews, edit‑and‑regen, and per/bulk downloads—all scaffolded from a single prompt Builder thread. This is the “vibe coding” workflow in practice for quick internal tools and spec UIs.
Single‑prompt iPhone mockup tool shipped with Gemini 3 + Anycoder
A designer spun up an iPhone mockup generator with one prompt using Gemini 3 and Anycoder—handy for slotting screenshots into device frames during reviews Announcement. You can try the live Space and inspect the approach Hugging Face space, with Anycoder’s updated UI also available for broader app scaffolding Anycoder space.
AI proposes a ‘newspaper’ redesign from an existing personal site
Matt Shumer asked Gemini 3 to redesign his website and got multiple directions, including a striking ‘newspaper’ variant that rethinks hierarchy and typography Before/after mocks. For rapid ideation, this is a low‑friction way to test layout voices before committing to components.
Lovart turns on Gemini 3 for rapid UI mockups and studies
Lovart says Gemini 3 is live on its platform for UI design tasks Feature note. A snowy triptych reel shows fast aesthetic exploration that can double as moodboards or screen backgrounds before moving to components.
Vibe‑coded web game lands with leaderboard, chat, and shareable scores
Built mostly in Google AI Studio with Gemini 3, “Tie Drop” demonstrates end‑to‑end prototyping speed: UI, gameplay, PNG score export, and live chat shipped in hours Game thread. It’s a concrete template for quickly testing UX loops and sharing builds for feedback Live game.
🎵 Auto‑scored cuts and accessible reading
New audio flows for editors and storytellers: Firefly scores videos directly from the cut, Producer speeds session recall, and ElevenLabs opens free reading access with NFB. Mostly tutorials and partnerships.
Adobe Firefly now scores your video automatically, with 4 track options and commercial-safe use
Adobe’s new Generate Soundtrack takes a video, auto-writes a music prompt from its pacing and mood, then returns four synced options you can tweak by vibe, style, tempo, and length—licensed for commercial use Feature brief. The step-by-step shows upload → auto-prompt → edit settings → re-generate → download, making it a direct-from-cut music pass for editors Tutorial steps Firefly soundtrack.
ElevenLabs partners with NFB to offer blind members free ElevenReader Ultra access
ElevenLabs’ Impact Program now gives National Federation of the Blind members a free 12‑month ElevenReader Ultra license, adding lifelike narration, screen‑reader compatibility, and user‑chosen voices for accessible reading at scale Partnership post ElevenLabs blog. Applications are open via the Impact Program, with the aim to support one million voices Program details.
Producer adds “Go to Session” to reopen any song’s timeline instantly
Producer rolled out “Go to Session,” a jump-back control under Song → Details that reopens the exact session you built the track in, so you can keep iterating without hunting through projects Feature note. It complements the new Memories context from earlier this week by speeding recall plus persistence of your creative state Memories feature.
🧊 Characters and 3D from text or a sketch
Character realism and rapid 3D asset creation get creator‑ready: Hedra’s Character‑3 HD reels plus a tool that turns text or 2D drawings into usable 3D models. Mostly hands‑on demos and promos.
Character‑3 HD promo and live dialogue tests
Hedra is pushing Character‑3 HD with a 2,500‑credit tryout (follow + RT + reply) and creators are already stress‑testing it for conversational performances model reel. Following up on realism reel that showed cinematic close‑ups and a tryout offer, today’s clips highlight natural back‑and‑forth with “real voices,” useful for character‑driven shorts and talking‑head ads creator test.
For teams, the draw is fast, photo‑faithful faces with enough consistency for sequential shots. Note: voice licensing still matters even if the face sells the scene.
Text or sketch to usable 3D with Aicad
Aicad App is getting creator attention for converting plain text or simple 2D drawings into production‑ready 3D models within seconds—pitched for engineering, prototyping, game dev, and 3D printing app overview. A creator example shows a functional laptop‑stand concept generated from a one‑line brief, underscoring its CAD‑leaning utility for practical parts as well as props product example.
The point is: it compresses the ideation→mesh loop. You’ll still want to verify tolerances and materials before fabrication, but for fast iterations this replaces hours of manual modeling.
Native 3D multimodal LLM teased by Tencent
Tencent’s Part‑X‑MLLM was teased as a native 3D multimodal LLM that unifies tasks like grounding, generation, and broader 3D understanding under one model paper mention. For 3D creators, the promise is fewer hops between segmentation, scene understanding, and asset creation—meaning faster blocking and cleaner handoffs into DCC tools.
If the model lands as described, expect better prompt‑to‑scene coherence and easier toolchains for character placement and object interaction in synthetic shots.
📚 Agentic research, model souping, and physical 3D assets
Paper drops relevant to creative workflows: stronger tool‑using agents, weight‑averaged model combos, Olympiad‑level physics reasoning, and single‑image → simulation‑ready 3D assets.
MiroThinker v1.0 scales to 600 tool calls with strong GAIA/HLE/BrowseComp scores
MiroMind’s open research agent runs with a 256K context and up to 600 tool calls per task, reporting 81.9% on GAIA, 37.7% on HLE, and 47.1% on BrowseComp. That’s useful for deep creative research, story bibles, and long web tasks without vendor lock‑in papers page, with a concise overview here paper thread.

PhysX‑Anything: single‑image → simulation‑ready 3D assets with new PhysX‑Mobility set
PhysX‑Anything introduces a framework to generate simulation‑ready, articulated 3D assets from one image, plus the PhysX‑Mobility dataset of 2,000+ objects. A new geometry tokenization cuts tokens ~193×, making explicit geometry learning feasible within common VLM budgets—promising for turning prop photos into physics‑rigged assets papers page.
Meta’s Souper‑Model shows non‑uniform “model soup” boosting function calling SOTA
Meta proposes Souper‑Model (SoCE), a Soup Of Category Experts that non‑uniformly weight‑averages expert checkpoints to raise state‑of‑the‑art on function calling and improve multilingual, math, and tool use—without retraining. For builders, it hints at a cheap performance bump by combining existing models rather than scaling one giant model ArXiv paper and a community read is underway discussion thread.

P1 physics models report IPhO gold‑medal performance; transfer gains to math/code
The P1 series, trained via reinforcement learning for physics reasoning, claims gold‑medal performance at IPhO 2025 (12 golds) and shows strong cross‑domain gains in math and coding. For VFX and simulation‑heavy workflows, better physics reasoning could auto‑check continuity and catch impossible motion papers page, with an earlier pointer here paper link.

📣 Deals, challenges, and hiring for creators
Platform promos and calls to create dominate: extended discounts, credit drops, and holiday challenges. Useful for teams planning budgeted experiments this week.
Higgsfield extends BFCM 3 days with a 9‑hour 300‑credit promo
Following up on Higgsfield BF (65% off + 300‑credit drop), the team apologized for earlier missteps and extended its Black Friday pricing by three more days Apology video. A separate social promo offers 300 free credits for a 9‑hour window if you retweet, follow, like, and comment—useful for testing image/video pipelines on a budget Credit giveaway.
Glif expands payment support to dozens of new countries
Glif rolled out support for payments in dozens of additional countries, addressing prior card declines tied to billing region Payments update. The move should make it easier for non‑US teams to pay and ship with Glif’s tooling; details align with Stripe’s global availability map Stripe availability.
Promise is hiring for 17 AI creative roles with equity
AI‑native studio Promise announced 17 open roles spanning AI storytelling and production, noting that positions include equity Hiring thread. If you want to work on AI‑led film and content pipelines, this is a rare chance to join an early team with ownership upside Equity note.

FLUX hosts a 32‑hour SF hackathon with $25K+ in prizes
BFL is hosting a 32‑hour FLUX hackathon in San Francisco on Nov 22–23 with 150 seats and $25K+ in prizes—build with FLUX models and ship by the buzzer Hackathon post. Partners include NVIDIA, DigitalOcean, Vercel, Anthropic, and Cerebral Valley, which signals strong infra and model support on site Partners update.

Pollo 2.0 launches a Christmas video challenge with cash rewards
Pollo AI kicked off a Christmas Holiday creator challenge running Nov 18–30, paying $2 for each selected entry. Submissions must use the Pollo 2.0 model; the post includes the rules and submission link for quick entry Challenge details. It’s a lightweight way to monetize short festive clips this week.

Verdent runs 70% off Gemini 3 Pro for 30 days with double credits
Verdent is discounting Gemini 3 Pro usage by 70% for 30 days and doubling credits on subscriptions Deal details. The platform pitches parallel, isolated Gemini sessions that plan → code → verify autonomously—worth a short, discounted trial if your current AI coding loop needs fewer handoffs.
💬 Creator discourse: critics, coping, and benchmark caution
Lively threads on AI art legitimacy, tactics for handling pile‑ons, and a reminder to trust hands‑on evals over leaderboard hype.
Karpathy urges hands-on model testing amid Gemini 3 leaderboard hype
Andrej Karpathy weighed in on Gemini 3, calling it a top-tier daily driver while warning that public benchmarks can be gamed via overfitting and should not replace direct A/B trials. He shared a telling anecdote: the model refused to accept it was 2025 until he enabled the web tool, underscoring why tool-use and real tasks matter in evaluation Summary thread.
Creators push back on “AI slop” label and reframe pro vs hobby debate
AI artists fired back at “slop” taunts, arguing that getting paid defines professionalism while tools are secondary to output and taste. The thread sparked heavy replies as creators leaned into market outcomes over medium purity and challenged gatekeeping around “real art” Pro vs hobby post Slop rebuttal Market frame Pile-on comment.
“Mute, don’t block” spreads as a playbook for handling AI hate-piles
A tactical post recommends muting persistent detractors instead of blocking, claiming it starves pile-ons of attention while preserving reach. The advice arrives alongside creators experimenting with reply gating and visibility settings to defuse brigades, following up on verified-only as an earlier pile-on tactic Muting tactic.
Creators float “intelligence per second” as a better way to judge models
Amid rapid releases compressing perceived progress, a creator proposed tracking “intelligence per second” to balance quality with speed, and noted scaling laws still feel intact even if jumps seem smaller due to cadence. It’s a nudge to weigh latency and throughput alongside benchmarks when choosing day-to-day tools Metric idea Scaling laws take.